
This chapter explains how to use Sparksee API to manage a Sparksee graph database and perform basic operations. Later sections include a detailed explanation of the following topics:
Moreover, higher functionality also available in the API is explained as well, including:
Most of the functionality provided by the Sparksee API is included in the com.sparsity.sparksee.gdb package or namespace in Sparkseejava and Sparkseenet respectively, and in the sparksee::gdb namespace in Sparkseecpp. If not, the specific package or namespace is indicated.
The construction of a Sparksee database includes the following steps:
Initialize the configuration. The basic default configuration only requires the instantiation of the SparkseeConfig class. And setting the license information. See the ‘Configuration’ chapter for a more detailed explanation of this instantiation & also check the advanced configuration options. But we recommend to create the SparkseeConfig with a path to a config file (it doesn’t have to exist yet) in order to be able to save the downloaded license key instead of having to download it every time.
Second, a new instance of Sparksee must be created. The configuration previously created is set-up during this instantiation. Sparksee is a Database factory which allows a Sparksee graph database to be opened or created.
Now it is time to create the database itself. A single Sparksee instance can open or create N different databases, but a database can only be concurrently accessed once - take a look at the ‘Processing’ section of the ‘Graph database’ chapter for more information. Each database created must have a unique path. Database is considered the Session factory.
A Session is a stateful period of activity of a user with a database. Therefore, the manipulation of a Database must be enclosed into a Session instance. A Database can only be accessed once, and multiple Session instances can be obtained from a Database instance. However, as sessions are not thread-safe, each thread must manage its own session. This is further explained in the ‘Processing’ section of the ‘Graph Database’ chapter
A Graph instance must be obtained from the Session, to perform graph-based operations on the graph database.
Sparksee, Database and Session must be closed (deleted in the case of C++) when they are no longer in use, to ensure all data is successfully flushed and persistently stored. Moreover, it is important that they are closed in the correct order, which is the reverse of their creation.
This example shows the construction of a new empty graph database. To open an already-existing Sparksee graph database the method Sparksee#open should be used instead of Sparksee#create. Also, it is possible to open the database in read-only mode by using the parameter read from the Sparksee#open method:
import com.sparsity.sparksee.gdb.*;
public class SparkseejavaTest
{
public static void main(String argv[])
throws java.io.IOException, java.lang.Exception
{
SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.setClientId("Your client identifier");
cfg.setLicenseId("Your license identifier");
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.create("HelloSparksee.gdb", "HelloSparksee");
Session sess = db.newSession();
Graph graph = sess.getGraph();
// Use 'graph' to perform operations on the graph database
sess.close();
db.close();
sparksee.close();
}
}using com.sparsity.sparksee.gdb;
public class SparkseenetTest
{
public static void Main()
{
SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.SetClientId("Your client identifier");
cfg.SetLicenseId("Your license identifier");
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.Create("HelloSparksee.gdb", "HelloSparksee");
Session sess = db.NewSession();
Graph graph = sess.GetGraph();
// Use 'graph' to perform operations on the graph database
sess.Close();
db.Close();
sparksee.Close();
}
}#include "gdb/Sparksee.h"
#include "gdb/Database.h"
#include "gdb/Session.h"
#include "gdb/Graph.h"
#include "gdb/Objects.h"
#include "gdb/ObjectsIterator.h"
using namespace sparksee::gdb;
int main(int argc, char *argv[])
{
SparkseeConfig cfg(L"sparksee.cfg");
cfg.SetClientId(L"Your client identifier");
cfg.SetLicenseId(L"Your license identifier");
Sparksee *sparksee = new Sparksee(cfg);
Database * db = sparksee->Create(L"HelloSparksee.gdb", L"HelloSparksee");
Session * sess = db->NewSession();
Graph * graph = sess->GetGraph();
// Use 'graph' to perform operations on the graph database
delete sess;
delete db;
delete sparksee;
return EXIT_SUCCESS;
}# -*- coding: utf-8 -*-
import sparksee
def main():
cfg = sparksee.SparkseeConfig("sparksee.cfg")
cfg.set_client_id("Your client identifier")
cfg.set_license_id("Your license identifier")
sparks = sparksee.Sparksee(cfg)
db = sparks.create(u"Hellosparks.gdb", u"HelloSparksee")
sess = db.new_session()
graph = sess.get_graph()
# Use 'graph' to perform operations on the graph database
sess.close()
db.close()
sparks.close()
if __name__ == '__main__':
main()#import <Foundation/Foundation.h>
#import <Sparksee/Sparksee.h>
int main(int argc, const char * argv[])
{
@autoreleasepool {
STSSparkseeConfig *cfg = [[STSSparkseeConfig alloc] initWithPath: @"sparksee.cfg"];
[cfg setClientId: @"Your client identifier"];
[cfg setLicenseId: @"Your license identifier"];
STSSparksee *sparksee = [[STSSparksee alloc] initWithConfig: cfg];
// If you are not using Objective-C Automatic Reference Counting , you
// may want to release the cfg here, when it's no longer needed.
//[cfg release];
STSDatabase *db = [sparksee create: @"HelloSparksee.gdb" alias: @"HelloSparksee"];
STSSession *sess = [db createSession];
STSGraph *graph = [sess getGraph];
// Use 'graph' to perform operations on the graph database
[sess close];
[db close];
[sparksee close];
// If you are not using Objective-C Automatic Reference Counting , you
// may want to release the sparksee here , when it's closed.
//[sparksee release];
}
return 0;
}Once an Sparksee instance is created using a SparkseeConfig (see the ‘Configuration’ chapter), most configuration settings can not be modified. The Cache maximum size is an exception. In a server dedicated to running the Sparksee graph database, once the Sparksee instance is created, you may never need to modify your initial settings. But in a device were Sparksee is not it’s main process, a dynamic modification of the maximum cache in use may be required.
For example, in a mobile platform the OS may require an application to release memory in order to give this scarce resource to another application. If you fail to release the memory, the process can be stopped. To handle this dynamic change there are a few new Database methods that can be helpful.
GetCacheMaxSize Returns the current cache maximum setting in megabytes.
SetCacheMaxSize Sets a new value for the cache maximum size (in megabytes). It may fail if the new value is too big or too small.
FixCurrentCacheMaxSize The current cache in use may have not reached the maximum setting yet. If it’s less than the maximum and more than the minimum required for the current pools, the current cache usage will be set as the maximum, so it will not grow anymore.
SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.setClientId("Your client identifier");
cfg.setLicenseId("Your license identifier");
cfg.setCacheMaxSize(1024); // 1GB Cache
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.create("HelloSparksee.gdb", "HelloSparksee");
Session sess = db.newSession();
Graph graph = sess.getGraph();
...
db.setCacheMaxSize(db.getCacheMaxSize()/2); // Try to reduce the Cache maximum in half
...SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.SetClientId("Your client identifier");
cfg.SetLicenseId("Your license identifier");
cfg.SetCacheMaxSize(1024); // 1GB Cache
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.Create("HelloSparksee.gdb", "HelloSparksee");
Session sess = db.NewSession();
Graph graph = sess.GetGraph();
...
db.SetCacheMaxSize(db.GetCacheMaxSize()/2); // Try to reduce the Cache maximum in half
...SparkseeConfig cfg(L"sparksee.cfg");
cfg.SetClientId(L"Your client identifier");
cfg.SetLicenseId(L"Your license identifier");
cfg.SetCacheMaxSize(1024); // 1GB Cache
Sparksee *sparksee = new Sparksee(cfg);
Database * db = sparksee->Create(L"HelloSparksee.gdb", L"HelloSparksee");
Session * sess = db->NewSession();
Graph * graph = sess->GetGraph();
...
db->SetCacheMaxSize(db->GetCacheMaxSize()/2); // Try to reduce the Cache maximum in half
...cfg = sparksee.SparkseeConfig("sparksee.cfg")
cfg.set_client_id("Your client identifier")
cfg.set_license_id("Your license identifier")
cfg.set_cache_max_size(1024) // 1GB
sparks = sparksee.Sparksee(cfg)
db = sparks.create(u"Hellosparks.gdb", u"HelloSparksee")
sess = db.new_session()
graph = sess.get_graph()
...
db.set_cache_max_size(db.get_cache_max_size()/2) // Try to reduce the Cache maximum in half
...STSSparkseeConfig *cfg = [[STSSparkseeConfig alloc] initWithPath: @"sparksee.cfg"];
[cfg setClientId: @"Your client identifier"];
[cfg setLicenseId: @"Your license identifier"];
[cfg setCacheMaxSize: 1024]; // 1GB
STSSparksee *sparksee = [[STSSparksee alloc] initWithConfig: cfg];
STSDatabase *db = [sparksee create: @"HelloSparksee.gdb" alias: @"HelloSparksee"];
STSSession *sess = [db createSession];
STSGraph *graph = [sess getGraph];
...
[db setCacheMaxSize: [db getCacheMaxSize]/2]; // Try to reduce the Cache maximum in half
...A graph database is a set of objects (nodes and edges) where each object belongs to a type. Node and edge types define the schema of the graph database and they are required to create new objects.
All types have a unique user-provided string identifier, the type name as well as a unique and immutable Sparksee-generated numeric identifier, the type identifier. The method Graph#newNodeType creates a new type of node.
The type identifier will be used to refer that type in all of the APIs requiring that information. For example: the Graph#newNode method, that creates a new node object, needs a single argument which is the node type identifier to establish that the new object will belong to that type.
Whereas node types only require a name for their construction, edge types have other options. Edge types can be directed or undirected and restricted or non-restricted. These topics are explained in the ‘Types’ section of the ‘Graph database’ chapter. Check out the parameters of Graph#newEdgeType and Graph#newRestrictedEdgeType methods in the reference guides to see how to set the different options. In addition, a specific index to improve some operations (such as neighbor retrieval) can be defined for edge types. To fully understand the benefits of this index, see the ‘Indexing’ section of the ‘Graph database’ chapter.
When a node or edge object is created (with Graph#newNode or Graph#newEdge respectively), a unique and immutable Sparksee-generated numeric identifier is returned. This identifier is known as the object identifier or OID. Thus, all operations on a node or edge object will require this OID as a parameter.
Note that on certain languages the api methods and classes may have slightly different names in order to conform to the language conventions. For instance, all the classes in Objective-C have a STS prefix (from Sparsity Technologies Sparksee), so the Graph#newNode and Graph#newEdge methods become STSGrah#createNode and STSGrah#createEdge. In the document explanations we will usually reference the classes and methods using the most common names (without prefixes), but the exact names can be seen on the code samples and can easily be found on the specific api language reference documentation.
The following examples include the creation of types and objects. We are creating 2 “PEOPLE” which have a relationship between them, “FRIEND”.
Graph graph = sess.getGraph();
...
int peopleTypeId = graph.newNodeType("PEOPLE");
int friendTypeId = graph.newEdgeType("FRIEND", true, true);
long people1 = graph.newNode(peopleTypeId);
long people2 = graph.newNode(peopleTypeId);
long friend1 = graph.newEdge(friendTypeId, people1, people2);Graph graph = sess.GetGraph();
...
int peopleTypeId = graph.NewNodeType("PEOPLE");
int friendTypeId = graph.NewEdgeType("FRIEND", true, true);
long people1 = graph.NewNode(peopleTypeId);
long people2 = graph.NewNode(peopleTypeId);
long friend1 = graph.NewEdge(friendTypeId, people1, people2);Graph * graph = sess->GetGraph();
...
type_t peopleTypeId = graph->NewNodeType(L"PEOPLE");
type_t friendTypeId = graph->NewEdgeType(L"FRIEND", true, true);
oid_t people1 = graph->NewNode(peopleTypeId);
oid_t people2 = graph->NewNode(peopleTypeId);
oid_t friend1 = graph->NewEdge(friendTypeId, people1, people2);graph = sess.get_graph()
...
people_type_id = graph.new_node_type(u"PEOPLE")
friend_type_id = graph.new_edge_type(u"FRIEND", True, True)
people1 = graph.new_node(people_type_id)
people2 = graph.new_node(people_type_id)
friend1 = graph.new_edge(friend_type_id, people1, people2)STSGraph *graph = [sess getGraph];
...
int peopleTypeId = [graph createNodeType: @"PEOPLE"];
int friendTypeId = [graph createEdgeType: @"FRIEND" directed: TRUE neighbors: TRUE];
long long people1 = [graph createNode: peopleTypeId];
long long people2 = [graph createNode: peopleTypeId];
long long friend1 = [graph createEdge: friendTypeId tail: people1 head: people2];Complementary to adding new node or edge types or adding new node or edge objects, Sparksee allows the removal of node or edges types and objects. Specifically, the method Graph#removeType removes a type and the method Graph#drop removes an object.
Other methods to interact with the schema are Graph#findType to discover if a type already exists, TypeList Graph#findTypes to retrieve all existing types and Type Graph#getType to get a specific type to be used in other operations.
The following examples create new node types called “PEOPLE” and edge types called “FRIEND”, if they do not previously exist. Then all existing types are traversed and removed. Note that the following examples contain methods regarding attributes that are explained in the next section, and are solely here to illustrate what kind of methods will be using the results from the types’ methods:
There are several restrictions to be able to remove a type:
It can not have any attribute. If it has attribute, you have to remove it’s attributes first.
If it’s a node type, It can not exist any restricted edge type using using the node type as head or tail. If that’s the case, you have to remove the restricted edge type first.
If it’s a node type, It can not exist any edge from an unrestricted edge type using any node of this type as a head or tail. If that’s the case, you have to drop the edge before trying to remove the node type.
In the following example, we could use FindTypes and try to remove all the types in one loop. But if we try to remove a node type with any of the previous restrictions before removing the conflicting edge types (or edges), the operation would fail.
So we will first get only the edge types (with FindEdgeTypes) instead of getting all the types (with FindTypes) to remove only the edge types. The procedure could then be safely repeated for the node types (with FindNodeTypes or with FindTypes because only node types remain) without the risk of any operation failing for the previous restricions because all the edge types would have been removed before. But we don’t show it in the sample code because it would be exactly the same changing only the method to get the types (FindNodeTypes).
Graph graph = sess.getGraph();
...
int peopleTypeId = graph.findType("people");
if (Type.InvalidType == peopleTypeId)
{
peopleTypeId = graph.newNodeType("people");
}
int friendTypeId = graph.findType("friend");
if (Type.InvalidType == friendTypeId)
{
friendTypeId = graph.newEdgeType("friend", true, true);
}
...
TypeList tlist = graph.findEdgeTypes();
TypeListIterator tlistIt = tlist.iterator();
while (tlistIt.hasNext())
{
int type = tlistIt.next();
Type tdata = graph.getType(type);
System.out.println("Type " + tdata.getName() + " with " + tdata.getNumObjects() + " objects");
AttributeList alist = graph.findAttributes(type);
AttributeListIterator alistIt = alist.iterator();
while (alistIt.hasNext())
{
int attr = alistIt.next();
Attribute adata = graph.getAttribute(attr);
System.out.println(" - Attribute " + adata.getName());
graph.removeAttribute(attr);
}
graph.removeType(type);
}Graph graph = sess.GetGraph();
...
int peopleTypeId = graph.FindType("people");
if (Type.InvalidType == peopleTypeId)
{
peopleTypeId = graph.NewNodeType("people");
}
int friendTypeId = graph.FindType("friend");
if (Type.InvalidType == friendTypeId)
{
friendTypeId = graph.NewEdgeType("friend", true, true);
}
...
TypeList tlist = graph.FindEdgeTypes();
TypeListIterator tlistIt = tlist.Iterator();
while (tlistIt.HasNext())
{
int type = tlistIt.Next();
Type tdata = graph.GetType(type);
System.Console.WriteLine("Type " + tdata.GetName() + " with " + tdata.GetNumObjects() + " objects");
AttributeList alist = graph.FindAttributes(type);
AttributeListIterator alistIt = alist.Iterator();
while (alistIt.HasNext())
{
int attr = alistIt.Next();
Attribute adata = graph.GetAttribute(attr);
System.Console.WriteLine(" - Attribute " + adata.GetName());
graph.RemoveAttribute(attr);
}
graph.RemoveType(type);
}Graph * graph = sess->GetGraph();
...
type_t peopleTypeId = graph->FindType(L"people");
if (InvalidType == peopleTypeId)
{
peopleTypeId = graph->NewNodeType(L"people");
}
type_t friendTypeId = graph->FindType(L"friend");
if (InvalidType == friendTypeId)
{
friendTypeId = graph->NewEdgeType(L"friend", true, true);
}
...
TypeList * tlist = graph->FindEdgeTypes();
TypeListIterator * tlistIt = tlist->Iterator();
while (tlistIt->HasNext())
{
type_t type = tlistIt->Next();
Type * tdata = graph->GetType(type);
std::wcout << L"Type " << tdata->GetName() << L" with " << tdata->GetNumObjects() << L" objects";
AttributeList * alist = graph->FindAttributes(type);
AttributeListIterator * alistIt = alist->Iterator();
while (alistIt->HasNext())
{
attr_t attr = alistIt->Next();
Attribute * adata = graph->GetAttribute(attr);
std::wcout << L" - Attribute " << adata->GetName();
delete adata;
graph->RemoveAttribute(attr);
}
delete alist;
delete alistIt;
delete tdata;
graph->RemoveType(type);
}
delete tlist;
delete tlistIt;graph = sess.get_graph()
...
people_type_id = graph.find_type(u"PEOPLE")
if people_type_id == sparksee.Type.INVALID_TYPE:
people_type_id = graph.new_node_type(u"PEOPLE")
friend_type_id = graph.find_type(u"FRIEND")
if friend_type_id == sparksee.Type.INVALID_TYPE:
friend_type_id = graph.new_edge_type(u"FRIEND", True, True)
...
type_list = graph.find_edge_types()
for my_type in type_list:
type_data = graph.get_type(my_type)
print "Type", type_data.get_name(), " with ", type_data.get_num_objects(), " objects"
attribute_list = graph.find_attributes(my_type)
for attribute in attribute_list:
attribute_data = graph.get_attribute(attribute)
print " - Attribute ", attribute_data.get_name()
graph.remove_attribute(attribute)
graph.remove_type(my_type)STSGraph *graph = [sess getGraph];
...
int peopleTypeId = [graph findType: @"people"];
if ([STSType getInvalidType] == peopleTypeId)
{
peopleTypeId = [graph createNodeType: @"people"];
}
int friendTypeId = [graph findType: @"friend"];
if ([STSType getInvalidType] == friendTypeId)
{
friendTypeId = [graph createEdgeType: @"friend" directed: TRUE neighbors: TRUE];
}
...
STSTypeList * tlist = [graph findEdgeTypes];
STSTypeListIterator * tlistIt = [tlist iterator];
while ([tlistIt hasNext])
{
int type = [tlistIt next];
STSType * tdata = [graph getType: type];
NSLog(@"Type %@ with %lld\n", [tdata getName], [tdata getNumObjects]);
STSAttributeList * alist = [graph findAttributes: type];
STSAttributeListIterator * alistIt = [alist iterator];
while ([alistIt hasNext])
{
int attr = [alistIt next];
STSAttribute * adata = [graph getAttribute: attr];
NSLog(@" - Attribute %@\n", [adata getName]);
[graph removeAttribute: attr];
}
[graph removeType: type];
}All node and edge types can have a set of attributes which are part of the schema of the graph database. An attribute should have a single value, and once created it is possible to set and get that value multiple times for each object.
In general, attributes are defined within the scope of a node or edge type and identified by a unique string identifier provided by the user. As is explained in the ‘Attributes’ section of the ‘Graph database’ chapter, it is possible to have two attributes with the same name but defined for two different types. For example, we could define the attribute “Name” for two different node types “PEOPLE” and “MOVIE”, resulting in two different attributes. Since attributes are defined within the scope of a type, only objects belonging to that type will be able to set and get values for that attribute.
The method to define a new attribute is Graph#newAttribute. As well as the parent type and the name, the definition of an attribute includes the datatype and the index-capabilities.
The datatype restricts the domain of the values for that attribute, thus all the objects having a non-null value for the attribute will have a value belonging to that domain. For example, in the previous example, all the objects having a value for the “Name” attribute will belong to the String datatype domain. Existing datatypes are defined in the Datatype enum class which includes the following:
The indexing-capabilities of an attribute determine the performance of the query operations on that attribute as is explained in the ‘Indexing’ section of the ‘Graph Database’ chapter. Different index options are defined in the AttributeKind enum class which includes basic, indexed and unique attributes.
The indexing-capabilities of an attribute can be updated later using the Graph#indexAttribute method.
When an object is created it will have the default value for all the attributes defined for the type of the new object (by default the attribute value is null). This default value can also be defined afterwards by using the method Graph#setAttributeDefaultValue.
Analogously to node and edge types, when an attribute is defined a unique and immutable Sparksee-generated numeric identifier is returned. This identifier is the attribute identifier and will be used for all those APIs requiring an attribute as a parameter, like the Graph#setAttribute method which sets a value for a given attribute and object (explained in next section).
Sparksee attributes are uni-valued. For multi-valued attributes you can use Array attributes. See ‘Array attributes’ section in this chapter.
Although the most common type of attributes are those whose scope is defined as type specific - Objects (node or edge objects) belonging to that type are the only ones allowed to set and get values for that attribute - we can also create attributes with a wider scope.
It is also possible to define the scope of an attribute as node specific using Type#NodesType as the parent type identifier argument when calling the Graph#newAttribute method. Whereas regular attributes are restricted to those objects belonging to the specified parent type, node attributes may be used for any node type in the graph. Therefore, any node of the graph, no matter which node type it belongs to, can set and get the values of a node attribute.
Analogous to the former kind is the user may define the scope of an attribute as edge specific using Type#EdgesType as the parent type identifier argument when calling the Graph#newAttribute method. Whereas regular attributes are restricted to those objects belonging to the specified parent type, node attributes may be used for any edge type in the graph. Therefore, any edge of the graph, no matter which edge type it belongs to, can set and get the values of a node attribute.
Finally, it is also possible to define the scope of an attribute as global using Type#GlobalType as the parent type identifier argument when calling the Graph#newAttribute method. Global attributes may be used for any object (node or edge) in the graph. Therefore, any object of the graph, no matter which type it belongs to, can set and get the values of a global attribute.
Whereas attributes and their values are persistent in the graph database (as types or objects), it is possible to create temporary or session attributes. Session attributes are a special type of attribute that are exclusively associated to the session:
They can only be seen and used within the session. Therefore other concurrent sessions cannot set, get or perform any operation with that attribute.
They are temporary and are automatically removed when the session is closed.
As they cannot be accessed outside the scope of a session or after it finishes, they are anonymous and do not require a name. Session attributes are created using the Graph#newSessionAttribute which returns the attribute identifier. Despite the restrictions, these attributes can be used in any method just like any other attribute.
The class Value is used to set and get attribute values for an object. This class is just the container for a specific value belonging to a specific data type (the domain). This class helps create a more simplified API. Thus, instead of having a different set/get method for each data type (for example: setAttributeInteger, setAttributeString, and so on), the user only manages two methods: one for setting the value and another one for getting it. As it is only a container, the value can be reused as many times as necessary. Actually, it is highly recommended that a Value instance is created only once and then different values set as many times as required. This behavior is illustrated in the following examples:
Graph graph = sess.getGraph();
...
int nameAttrId = graph.findAttribute(peopleTypeId, "Name");
if (Attribute.InvalidAttribute == nameAttrId)
{
nameAttrId = graph.newAttribute(peopleTypeId, "Name", DataType.String, AttributeKind.Indexed);
}
long people1 = graph.newNode(peopleTypeId);
long people2 = graph.newNode(peopleTypeId);
Value v = new Value();
graph.setAttribute(people1, nameAttrId, v.setString("Scarlett Johansson"));
graph.setAttribute(people2, nameAttrId, v.setString("Woody Allen"));Graph graph = sess.GetGraph();
...
int nameAttrId = graph.FindAttribute(peopleTypeId, "Name");
if (Attribute.InvalidAttribute == nameAttrId)
{
nameAttrId = graph.NewAttribute(peopleTypeId, "Name", DataType.String, AttributeKind.Indexed);
}
long people1 = graph.NewNode(peopleTypeId);
long people2 = graph.NewNode(peopleTypeId);
Value v = new Value();
graph.SetAttribute(people1, nameAttrId, v.SetString("Scarlett Johansson"));
graph.SetAttribute(people2, nameAttrId, v.SetString("Woody Allen"));Graph * graph = sess->GetGraph();
...
attr_t nameAttrId = graph->FindAttribute(peopleTypeId, L"Name");
if (InvalidAttribute == nameAttrId)
{
nameAttrId = graph->NewAttribute(peopleTypeId, L"Name", String, Indexed);
}
oid_t people1 = graph->NewNode(peopleTypeId);
oid_t people2 = graph->NewNode(peopleTypeId);
Value v;
graph->SetAttribute(people1, nameAttrId, v.SetString(L"Scarlett Johansson"));
graph->SetAttribute(people2, nameAttrId, v.SetString(L"Woody Allen"));graph = sess.get_graph()
...
name_attr_id = graph.find_attribute(people_type_id, u"Name")
if sparksee.Attribute.INVALID_ATTRIBUTE == name_attr_id:
name_attr_id = graph.new_attribute(people_type_id, u"Name", sparksee.DataType.STRING, sparksee.AttributeKind.INDEXED)
people1 = graph.new_node(people_type_id)
people2 = graph.new_node(people_type_id)
v = sparksee.Value()
graph.set_attribute(people1, name_attr_id, v.set_string(u"Scarlett Johansson"))
graph.set_attribute(people2, name_attr_id, v.set_string(u"Woody Allen"))STSGraph *graph = [sess getGraph];
...
int nameAttrId = [graph findAttribute: peopleTypeId name: @"name"];
if ([STSAttribute getInvalidAttribute] == nameAttrId)
{
nameAttrId = [graph createAttribute: peopleTypeId name: @"name" dt: STSString kind: STSIndexed];
}
long long people1 = [graph createNode: peopleTypeId];
long long people2 = [graph createNode: peopleTypeId];
STSValue *v = [[STSValue alloc] init];
[graph setAttribute: people1 attr: nameAttrId value: [v setString: @"Scarlett Johansson"]];
[graph setAttribute: people2 attr: nameAttrId value: [v setString: @"Woody Allen"]];A Graph#setAttribute overload is also provided to set all the values of an attribute to a specific value (not only for a specific object). Additionally to Graph#setAttribute and Graph#getAttribute, there are other methods to manage attributes:
Graph#removeAttribute removes the attribute and its values.AttributeList Graph#findAttributes(int type) retrieves all attributes defined for the given type.AttributeList Graph#getAttributes(long object) retrieves all the attributes for the given object which have a non-null value.AttributeStatistics Graph#getAttributeStatistics(long attr) and long Graph#getAttributeIntervalCount retrieve some statistics for the given attribute (this is explained more in detail in the ‘Statistics’ section of the ‘Maintenance and monitoring’ chapter).Graph#indexAttribute updates the index-capability of the given attribute.Attribute Graph#getAttribute retrieves all the metadata associated with an existing attribute.String attribute values are restricted to a maximum length of 2048 characters, thus in case of storing larger strings, text attributes should be used instead. However, it is important to notice that whereas string attributes are set and got using the Value class, text attributes are operated using a stream pattern.
Text attributes can be considered a special case for the following reasons:
Graph#getAttributeText gets the value for a given object identifier by means of a TextStream instance instead of the Graph#getAttribute method and a Value instance.Graph#setAttributeText sets the value for a given object identifier by means of a TextStream instance instead of the Graph#setAttribute method and a Value instance.The TextStream class implements the stream pattern for Sparksee text attributes as follows:
The following examples show how to set a text attribute:
Graph graph = sess.getGraph();
...
long oid = ... // object identifier
int textAttrId = ... // text attribute identifier
...
String str1 = "This is the first chunk of the text stream";
String str2 = "This is the second chunk of the text stream";
...
TextStream tstrm = new TextStream(false);
graph.setAttributeText(oid, textAttrId, tstrm);
...
char[] buff = str1.toCharArray();
tstrm.write(buff, buff.length);
buff = str2.toCharArray();
tstrm.write(buff, buff.length);
tstrm.close();Graph graph = sess.GetGraph();
...
long oid = ... // object identifier
int textAttrId = ... // text attribute identifier
...
string str1 = "This is the first chunk of the text stream";
string str2 = "This is the second chunk of the text stream";
...
TextStream tstrm = new TextStream(false);
graph.SetAttributeText(oid, textAttrId, tstrm);
...
char[] buff = str1.ToCharArray();
tstrm.Write(buff, buff.Length);
buff = str2.ToCharArray();
tstrm.Write(buff, buff.Length);
tstrm.Close();Graph * graph = sess->GetGraph();
...
oid_t oid = ... // object identifier
attr_t textAttrId = ... // text attribute identifier
...
std::wstring str1(L"This is the first chunk of the text stream");
std::wstring str2(L"This is the second chunk of the text stream");
...
TextStream tstrm(false);
graph->SetAttributeText(oid, textAttrId, &tstrm);
...
tstrm.Write(str1.c_str(), str1.size());
tstrm.Write(str2.c_str(), str2.size());
tstrm.Close();graph = sess.get_graph()
...
oid = ... # object identifier
text_attribute_id = ... # text attribute identifier
...
str1 = u"This is the first chunk of the text stream"
str2 = u"This is the second chunk of the text stream"
...
tstrm = sparksee.TextStream(False)
graph.set_attribute_text(oid, text_attribute_id, tstrm)
...
tstrm.write(str1, len(str1))
tstrm.write(str2, len(str2))
tstrm.close()STSGraph *graph = [sess getGraph];
...
long long oid = ...; // object identifier
int textAttrId = ...; // text attribute identifier
...
NSString * const str1 = @"This is the first chunk of the text stream";
NSString * const str2 = @"This is the second chunk of the text stream";
...
STSTextStream *tstrm = [[STSTextStream alloc] initWithAppend: false];
[graph setAttributeText: oid attr: textAttrId tstream: tstrm];
...
[tstrm writeString: str1];
[tstrm writeString: str2];
[tstrm close]; // The stream must be closed
//[tstrm release]; // You may need to release it here.The following code blocks show an example of how the previously written text could be retrieved:
It’s important to always close the TextStream object retrieved, even if it’s content is Null.
Graph graph = sess.getGraph();
...
long oid = ... // object identifier
int textAttrId = ... // text attribute identifier
...
TextStream tstrm = graph.getAttributeText(oid, textAttrId);
if (!tstrm.isNull())
{
int read;
StringBuffer str = new StringBuffer();
do
{
char[] buff = new char[10];
read = tstrm.read(buff, 10);
str.append(buff, 0, read);
}
while (read > 0);
System.out.println(str);
}
tstrm.close();Graph graph = sess.GetGraph();
...
long oid = ... // object identifier
int textAttrId = ... // text attribute identifier
...
TextStream tstrm = graph.GetAttributeText(oid, textAttrId);
if (!tstrm.IsNull())
{
int read;
System.Text.StringBuilder str = new System.Text.StringBuilder();
do
{
char[] buff = new char[10];
read = tstrm.Read(buff, 10);
str.Append(buff, 0, read);
}
while (read > 0);
System.Console.WriteLine(str);
}
tstrm.Close();Graph * graph = sess->GetGraph();
...
oid_t oid = ... // object identifier
attr_t textAttrId = ... // text attribute identifier
...
TextStream *tstrm = graph->GetAttributeText(oid, textAttrId);
if (!tstrm->IsNull())
{
int read;
std::wstring str;
do
{
wchar_t * buff = new wchar_t[10];
read = tstrm->Read(buff, 10);
str.append(buff, read);
}
while (read > 0);
std::wcout << str << std::endl;
}
tstrm->Close();
delete tstrm;Graph * graph = sess->GetGraph();
...
oid = ... # object identifier
text_attribute_id = ... # text attribute identifier
...
tstrm = graph.get_attribute_text(oid, text_attribute_id)
if not tstrm.is_null():
readed_character = tstrm.read(1)
readedStr = readed_character
while len(readed_character) > 0:
readed_character = tstrm.read(10)
readedStr = readedStr + readed_character
print readedStr
tstrm.close()STSGraph *graph = [sess getGraph];
...
long long oid = ...; // object identifier
int textAttrId = ...; // text attribute identifier
...
STSTextStream *tstrm = [graph getAttributeText: oid attr: textAttrId];
if (![tstrm IsNull])
{
int readedSize;
NSMutableString * str = [[NSMutableString alloc] init];
do
{
NSString *next10chars = [tstrm readString: 10];
[str appendString: next10chars];
readedSize = [next10chars length];
}
while (readedSize > 0);
NSLog(@"Readed text:\n%@\n", str);
}
[tstrm close];
//[tstrm release];Array attributes are use to assign multi-valued attributes to nodes and/or edges. All but Text and String DataTypes are supported.
Like Text attributes, Array attributes are also considered a special case for the following reasons:
Graph#newArrayAttribute creates a new array attribute for a given node/edge type, given basic DataType and with a given number of dimensions.Graph#setArrayAttribute and Graph#setArrayAttributeVoid initialize an array attribute for a given object identifier with all dimensions set to the specified value. The former returns the array by means of a ValueArray instance.Graph#getArrayAttribute gets the currently set array by means of a ValueArray instance which can be used to manipulate the array through the different overloads of ValueArray#Set and ValueArray#Get methods.The ValueArray class allows accessing the contents of an array through the following methods:
ValueArray#Set to set the value at a specific dimension. The DataType of the given value must be the same of the Array DataType. An overload that does not take the dimension argument is provided to initialize all the dimensions of the array to a given value.ValueArray#SetX where X is the DataType (e.g. Integer, Double, Boolean, etc.) to set a ValueArray with the contents of buffer. Text and String Arrays are not currently supported.ValueArray#Get to get the value at a specific dimension.ValueArray#GetX where X is the DataType to read the contents of an array into a buffer.ValueArray#MakeNull to remove the array from the databaseValueArray#Sizeto get the number of dimensions in the arrayThe following examples show how to set an Array attribute:
Graph graph = sess.getGraph();
...
int type = ... // node or edge type
long oid = ... // object identifier
// Creates an Double array attribute with 32 dimensions
int arrayAttrId = graph.newArrayAttribute(type, "name", DataType.Double, 32);
Value value = new Value();
value.setDouble(0.0);
ValueArray vArray = graph.setArrayAttribute(oid, arrayAttrId, value);
for(int i = 0; i < vArray.size(); ++i) {
vArray.set(i, value.setDouble(i*1.0));
}
vArray.close();Graph graph = sess.GetGraph();
...
int type = ... // node or edge type
long oid = ... // object identifier
// Creates an Double array attribute with 32 dimensions
int arrayAttrId = graph.NewArrayAttribute(type, "name", DataType.Double, 32);
Value value = new Value();
value.SetDouble(0.0);
ValueArray vArray = graph.SetArrayAttribute(oid, arrayAttrId, value);
for(int i = 0; i < vArray.Size(); ++i) {
vArray.Set(i, value.setDouble(i*1.0));
}
vArray.Close();Graph * graph = sess->GetGraph();
...
int type = ... // node or edge type
long oid = ... // object identifier
// Creates an Double array attribute with 32 dimensions
int arrayAttrId = graph->NewArrayAttribute(type, L"name", Double, 32);
Value value;
value.SetDouble(0.0);
ValueArray* vArray = graph.SetArrayAttribute(oid, arrayAttrId, value);
for(int i = 0; i < vArray.Size(); ++i) {
vArray->Set(i, value.SetDouble(i*1.0));
}
delete ValueArray;graph = sess.get_graph()
type = ... // node or edge type
oid = ... // object identifier
// Creates an Double array attribute with 32 dimensions
array_attr_id = graph.new_array_attribute(type, "name", Double, 32)
value = sparksee.Value()
value.set_double(0.0)
varray = graph.set_array_attribute(oid, array_attr_id, value)
for(int i in range(0, varray.size()):
varray.set(i, value.set_double(i*1.0))
varray.close()STSGraph *graph = [sess getGraph];
...
int type = ...; // node or edge type
long long oid = ...; // object identifier
// Creates an Double array attribute with 32 dimensions
int arrayAttrId = [graph createArrayAttribute: [STSType type] name: @"name" dt: STSDouble size: arraySize];
STSValue* v = [[STSValue alloc] init];
[value setDouble: 0.0]
STSValueArray* va = [g setArrayAttribute: oid arayAttrId: ntArrayD value: v];
for(int i = 0; i < [va Size]; ++i)
{
[va setAt: i value: i*1.0];
}
[value release];
[va close];
[va release];As we are going to see later, most of the query or navigational operations return a collection of object identifiers or OIDs as the result of the operation. The Objects class is used for the management of these collections of object identifiers. Actually, Objects is considered a set, as duplicated elements are not allowed and it does not follow a defined order.
The user can create as many Objects instances as may be required for use by calling Objects Session#newObjects. Please note that the Objects class has been designed to store a large collection of object identifiers. Therefore, for smaller collections it is strongly recommended that a common class provided by the chosen language is used.
Also, it is important to note that this class is not thread-safe, so it cannot be used by two different threads at the same time.
The Objects class can add object identifiers to a collection (Objects#add), check if an object identifier exists (Objects#exists), remove an object identifier from the set (Objects#remove) or retrieve the number of elements of a collection (Objects#count). Take a look at the Objects class reference documentation to get a comprehensive list of all the available methods.
The following code blocks show some examples of the use of the Objects class:
Objects objs = sess.newObjects();
assert objs.add(1) && objs.add(2);
assert !objs.add(1);
assert objs.exists(1) && objs.exists(2) && !objs.exists(3);
assert objs.count() == 2 && !objs.isEmpty();
...
objs.close();Objects objs = sess.NewObjects();
System.Diagnostics.Debug.Assert(objs.Add(1) && objs.Add(2));
System.Diagnostics.Debug.Assert(!objs.Add(1));
System.Diagnostics.Debug.Assert(objs.Exists(1) && objs.Exists(2) && !objs.Exists(3));
System.Diagnostics.Debug.Assert(objs.Count() == 2);
...
objs.Close();Objects * objs = sess->NewObjects();
assert(objs->Add(1) && objs->Add(2));
assert(!objs->Add(1));
assert(objs->Exists(1) && objs->Exists(2) && !objs->Exists(3));
assert(objs->Count() == 2);
...
delete objs;objs = sess.new_objects()
assert(objs.add(1) and objs.add(2))
assert(not objs.add(1))
assert(objs.exists(1) and objs.exists(2) and not objs.exists(3))
assert(objs.count() == 2)
...
objs.close()STSObjects * objs = [sess createObjects];
assert([objs add: 1] && [objs add: 2]);
assert(![objs add: 1]);
assert([objs exists: 1] && [objs exists: 2] && ![objs exists: 3]);
assert([objs count] == 2);
[objs close];As seen in the previous examples, all Objects instances need to be closed (deleted in the case of C++) just like Sparksee, Database and Session instances. Moreover, collections must be closed as soon as possible to free internal resources and ensure a higher performance of the application.
Furthermore, as these collections are retrieved from the Session they are only valid while the parent Session instance remains open. In fact, when the Session is closed (deleted in the case of C++), it checks out if there are still any non-closed Objects instances, and if detected an exception is thrown.
The ObjectsIterator class is used to construct an iterator instance for traversing a collection. The traversal can be performed by calling the Objects#hastNext and Objects#next methods:
Objects objs = sess.newObjects();
...
ObjectsIterator it = objs.iterator();
while (it.hasNext())
{
long currentOID = it.next();
}
it.close();
...
objs.close();Objects objs = sess.NewObjects();
...
ObjectsIterator it = objs.Iterator();
while (it.HasNext())
{
long currentOID = it.Next();
}
it.Close();
...
objs.Close();Objects * objs = sess->NewObjects();
...
ObjectsIterator * it = objs->Iterator();
while (it->HasNext())
{
oid_t currentOID = it->Next();
}
delete it;
...
delete objs;STSObjects * objs = [sess createObjects];
...
STSObjectsIterator * it = [objs iterator];
while ([it hasNext])
{
long long currentOID = [it next];
}
[it close];
...
[objs close];It is important to notice that ObjectsIterator instances must be closed (deleted in the case of C++) as soon as possible to ensure better performance. Nevertheless, non-closed iterators will be automatically closed when the collection is closed.
When traversing Objects instances it is important to have in mind that the Objects instance cannot be updated; elements cannot be added or removed from the collection.
Objects instances can be efficiently combined with the following methods. Note that there are two versions for the same call, because whereas the instance method performs the resulting operation on the calling instance, the static method creates a new instance as a result of the operation.
Union.
Objects#union(Objects objs) & static Objects Objects#combineUnion(Objects objs1, Objects objs2)
The resulting collection contains the union of both collections with no repeated objects. It contains all the object identifiers from the first collection together with all the object identifiers from the second one.
Intersection.
Objects#intersection(Objects objs) & static Objects Objects#combineIntersection(Objects objs1, Objects objs2)
The resulting collection contains the intersection of both collections. It contains only those object identifiers from the first collection that also belong to the second one.
Difference.
Objects#difference(Objects objs) & static Objects Objects#combineDifference(Objects objs1, Objects objs2)
The resulting collection contains the difference of both collections. It contains those object identifiers from the first collection that do not belong to the second one.
Blow are some examples of the use of the three combination methods:
Objects objsA = sess.newObjects();
objsA.add(1);
objsA.add(2);
Objects objsB = sess.newObjects();
objsB.add(2);
objsB.add(3);
Objects union = Objects.combineUnion(objsA, objsB);
assert union.exists(1) && union.exists(2) && union.exists(3) && union.count() == 3;
union.close();
Objects intersec = Objects.combineIntersection(objsA, objsB);
assert intersec.exists(2) && intersec.count() == 1;
intersec.close();
Objects diff = Objects.combineDifference(objsA, objsB);
assert diff.exists(1) && diff.count() == 1;
diff.close();
objsA.close();
objsB.close();Objects objsA = sess.NewObjects();
objsA.Add(1);
objsA.Add(2);
Objects objsB = sess.NewObjects();
objsB.Add(2);
objsB.Add(3);
Objects union = Objects.CombineUnion(objsA, objsB);
System.Diagnostics.Debug.Assert(union.Exists(1) && union.Exists(2) && union.Exists(3) && union.Count() == 3);
union.Close();
Objects intersec = Objects.CombineIntersection(objsA, objsB);
System.Diagnostics.Debug.Assert(intersec.Exists(2) && intersec.Count() == 1);
intersec.Close();
Objects diff = Objects.CombineDifference(objsA, objsB);
System.Diagnostics.Debug.Assert(diff.Exists(1) && diff.Count() == 1);
diff.Close();
objsA.Close();
objsB.Close();Objects * objsA = sess->NewObjects();
objsA->Add(1);
objsA->Add(2);
Objects * objsB = sess->NewObjects();
objsB->Add(2);
objsB->Add(3);
Objects * unnion = Objects::CombineUnion(objsA, objsB);
assert(unnion->Exists(1) && unnion->Exists(2) && unnion->Exists(3) && unnion->Count() == 3);
delete unnion;
Objects * intersec = Objects::CombineIntersection(objsA, objsB);
assert(intersec->Exists(2) && intersec->Count() == 1);
delete intersec;
Objects * diff = Objects::CombineDifference(objsA, objsB);
assert(diff->Exists(1) && diff->Count() == 1);
delete diff;
delete objsA;
delete objsB;objsA = sess.new_objects()
objsA.add(1)
objsA.add(2)
objsB = sess.new_objects()
objsB.add(2)
objsB.add(3)
union = sparksee.Objects.combine_union(objsA, objsB)
assert(union.exists(1) and union.exists(2) and union.exists(3) and union.count() == 3)
union.close()
intersec = sparksee.Objects.combine_intersection(objsA, objsB)
assert(intersec.exists(2) and intersec.count() == 1)
intersec.close()
diff = sparksee.Objects.combine_difference(objsA, objsB)
assert(diff.exists(1) and diff.count() == 1)
diff.close()
objsA.close()
objsB.close()STSObjects * objsA = [sess createObjects];
[objsA add: 1];
[objsA add: 2];
STSObjects * objsB = [sess createObjects];
[objsB add: 2];
[objsB add: 3];
STSObjects * unnion = [STSObjects combineUnion: objsA objs2: objsB];
assert([unnion exists: 1] && [unnion exists: 2] && [unnion exists: 3] && [unnion count] == 3);
[unnion close];
STSObjects * intersec = [STSObjects combineIntersection: objsA objs2: objsB];
assert([intersec exists: 2] && [intersec count] == 1);
[intersec close];
STSObjects * diff = [STSObjects combineDifference: objsA objs2: objsB];
assert([diff exists: 1] && [diff count] == 1);
[diff close];
[objsA close];
[objsB close];Sparksee has different methods to retrieve data from the graph. Most of them return an instance of the Objects class.
The most simple query method is the select operation Objects Graph#select(int type), which retrieves all the objects belonging to the given node or edge type, so it is a type-based operation.
The method Objects Graph#select(int attribute, Condition cond, Value v) is more specific than the previous selection, being able to retrieve all the objects satisfying a condition for a given attribute. This select is an attribute-based operation.
Note that the second select operation requires the datatype of the given value to be the same as the datatype of the attribute.
This is the list of possible conditions to be specified in a select operation, all of them defined in the Condition enum class:
Equal: retrieves those objects that have a value for the attribute equal to the given value.
NotEqual: retrieves those objects that have a value for the attribute not equal to the given value.
GreaterEqual: retrieves those objects that have a value for the attribute greater than or equal to the given value.
GreaterThan: retrieves those objects that have a value for the attribute strictly greater than the given value.
LessEqual: retrieves those objects that have a value for the attribute less than or equal to the given value.
LessThan: retrieves those objects that have a value for the attribute strictly less than the given value.
Between: retrieves those objects that have a value for the attribute within the range defined for the two given values. This condition can only be used in the specific signature of the selected method where there are two argument values instead of one: Objects Graph#select(int attribute, Condition cond, Value lower, Value higher). Note that lower and higher define an inclusive range [lower,higher], also null values cannot be used in the specification of the range.
There are a few further conditions which can only be used for string attributes:
Like: retrieves those objects having a value which is a substring of the given value.
LikeNoCase: retrieves those objects having a value which is a substring (not case sensitive) of the given value.
RegExp: retrieves those objects having a value for the given attribute that matches a regular expression defined by the given string value. In fact, Like and LikeNoCase are simply two specific cases of regular expressions. More details on how Sparksee regular expressions work are given in a later section.
The following code blocks are examples of the select queries. Notice the use of the conditions:
Graph graph = sess.getGraph();
Value v = new Value();
...
// retrieve all 'people' node objects
Objects peopleObjs1 = graph.select(peopleTypeId);
...
// retrieve Scarlett Johansson from the graph, which is a "PEOPLE" node
Objects peopleObjs2 = graph.select(nameAttrId, Condition.Equal, v.setString("Scarlett Johansson"));
...
// retrieve all 'PEOPLE' node objects having "Allen" in the name. It would retrieve
// Woody Allen, Tim Allen or Allen Leech, or other similar if they are present in the graph.
Objects peopleObjs3 = graph.select(nameAttrId, Condition.Like, v.setString("Allen"));
...
peopleObjs1.close();
peopleObjs2.close();
peopleObjs3.close();Graph graph = sess.GetGraph();
Value v = new Value();
...
// retrieve all 'people' node objects
Objects peopleObjs1 = graph.Select(peopleTypeId);
...
// retrieve Scarlett Johansson from the graph, which is a "PEOPLE" node
Objects peopleObjs2 = graph.Select(nameAttrId, Condition.Equal, v.SetString("Scarlett Johansson"));
...
// retrieve all 'PEOPLE' node objects having "Allen" in the name. It would retrieve
// Woody Allen, Tim Allen or Allen Leech, or other similar if they are present in the graph.
Objects peopleObjs3 = graph.Select(nameAttrId, Condition.Like, v.SetString("Allen"));
...
peopleObjs1.Close();
peopleObjs2.Close();
peopleObjs3.Close();Graph * graph = sess->GetGraph();
Value v;
...
// retrieve all 'people' node objects
Objects * peopleObjs1 = graph->Select(peopleTypeId);
...
// retrieve Scarlett Johansson from the graph, which is a "PEOPLE" node
Objects * peopleObjs2 = graph->Select(nameAttrId, Equal, v.SetString(L"Scarlett Johansson"));
...
// retrieve all 'PEOPLE' node objects having "Allen" in the name. It would retrieve
// Woody Allen, Tim Allen or Allen Leech, or other similar if they are present in the graph.
Objects * peopleObjs3 = graph->Select(nameAttrId, Like, v.SetString(L"Allen"));
...
delete peopleObjs1;
delete peopleObjs2;
delete peopleObjs3;graph = sess.get_graph()
v = sparksee.Value()
...
# retrieve all 'people' node objects
people_objs1 = graph.select(people_type_id)
...
# retrieve Scarlett Johansson from the graph, which is a "PEOPLE" node
people_objs2 = graph.select(name_attr_id, sparksee.Condition.EQUAL, v.set_string(u"Scarlett Johansson"))
...
# retrieve all 'PEOPLE' node objects having "Allen" in the name. It would retrieve
# Woody Allen, Tim Allen or Allen Leech, or other similar if they are present in the graph.
people_objs3 = graph.select(name_attr_id, sparksee.Condition.LIKE, v.set_string("Allen"))
...
people_objs1.close()
people_objs2.close()
people_objs3.close()STSGraph *graph = [sess getGraph];
STSValue *v = [[STSValue alloc] init];
...
// retrieve all 'people' node objects
STSObjects * peopleObjs1 = [graph selectWithType: peopleTypeId];
...
// retrieve Scarlett Johansson from the graph, which is a "PEOPLE" node
STSObjects * peopleObjs2 = [graph selectWithAttrValue: nameAttrId cond: STSEqual value: [v setString: @"Scarlett Johansson"]];
...
// retrieve all 'PEOPLE' node objects having "Allen" in the name. It would retrieve
// Woody Allen, Tim Allen or Allen Leech, or other similar if they are present in the graph.
STSObjects * peopleObjs3 = [graph selectWithAttrValue: nameAttrId cond: STSLike value: [v setString: @"Allen"]];
...
[peopleObjs1 close];
[peopleObjs2 close];
[peopleObjs3 close];The method long Graph#findObject(long attr, Value v) is a special case of the attribute-based select operation. In this case, instead of returning a collection of objects, this method returns a single object identifier. Moreover, in this case, findObject assumes the condition Equal. Thus, it randomly returns the object identifier of any of the objects having the given value for the given attribute. Although it can be used with any kind of attribute (Basic, Indexed, Unique) it may be better to use it with Unique attributes, as they ensure that two objects will not have the same attribute value (except for the null value).
When retrieving an Objects from the graph and traversing the collection, as it is not a copy but directly access to Sparksee internal structures, any object cannot be removed or added from that collection. For example, if we traverse a collection of objects belonging to a certain type, we cannot remove elements from that type at the same time.
Similar to Objects Graph#select(int attribute, Condition cond, Value v), Sparksee provides a method to query for the Top K objects with a given attribute value. Such method is called KeyValues Graph#topK(int attribute, Condition cond, Value v, Order order, int k)` and returns a KeyValues iterator to the first k KeyValue pairs for a given condition and order.
Value v = new Value();
KeyValues kv = graph.topK(attrType, Condition.LessThan, v.setDouble(0.5), Order.Ascendent, 100);
while(kv.hasNext())
{
KeyValue kvp = kv.next();
long oidAux = kvp.getKey();
Value v = kvp.getValue();
...
}
kv.close();Value v = new Value();
KeyValues kv = graph.TopK(attrType, Condition.LessThan, v.setDouble(0.5), Order.Ascendent, 100);
while(kv.HasNext())
{
KeyValue kvp = kv.Next();
long oidAux = kvp.GetKey();
Value v = kvp.GetValue();
...
}
kv.Close();Value v;
KeyValues* kv = graph.TopK(attrType, LessThan, v.SetDouble(0.5), Ascendent, 100);
while(kv.HasNext())
{
KeyValue kvp;
kv.Next(kvp);
oid_t oidAux = kvp.GetKey();
Value v = kvp.GetValue();
...
}
delete kv;v = sparksee.Value
kv = g.top_k(attrType, sparksee.Condition.LESS_THAN, v.set_double(0.5), sparksee.Order.ASCENDENT, 100)
for kvp in kv:
oid = kvp.get_key()
v = kvp.get_value()
...
kv.close()STSValue *v = [[STSValue alloc] init];
STSKeyValues* kv = [g topkWithAttr: attrType cond: STSLessThan value: [v setDouble: 0.5] order: STSDescendent k: 100];
STSKeyValue* kvp = [[STSKeyValue alloc] init];
while ([kv hasNext]) {
[kv nextKeyValue: kvp];
long long oid = [kvp getKey];
STSValue* value = [kvp getValue];
...
}
[kv close];As explained previously, a regular expression can be used in query operations to search for objects having a value for an attribute matching the given regular expression. RegExp is the Condition value to set a matching regular expression condition in an attribute-based select operation. Of course, this condition can only be applied for string attributes.
Regular expression format conforms to most of the POSIX Extended Regular Expressions and therefore they are case sensitive.
A detailed reference for the syntax of the regular expressions can be found in the POSIX Extended Regular Expressions reference guide.
For instance the following regular expressions will have these matches:
A+B*C+ matches AAABBBCCCD
B*C+ matches AAACCCD
B+C+ does not match AAACCCD
^A[^]*D$ matches AAACCCD
B*C+$ does not match AAACCCD
The following examples search for people with names that start with an ‘A’ and end with a ‘D’, using regular expressions:
Graph graph = sess.getGraph();
Value v = new Value();
...
// retrieve all 'people' node objects having a value for the 'name' attribute
// satisfying the the '^A[^]*D$' regular expression
Objects peopleObjs = graph.select(nameAttrId, Condition.RegExp, v.setString("^A[^]*D$"));
...
peopleObjs.close();Graph graph = sess.GetGraph();
Value v = new Value();
...
// retrieve all 'people' node objects having a value for the 'name' attribute
// satisfying the the '^A[^]*D$' regular expression
Objects peopleObjs = graph.Select(nameAttrId, Condition.RegExp, v.SetString("^A[^]*D$"));
...
peopleObjs.Close();Graph * graph = sess->GetGraph();
Value v;
...
// retrieve all 'people' node objects having a value for the 'name' attribute
// satisfying the the '^A[^]*D$' regular expression
Objects * peopleObjs = graph->Select(nameAttrId, RegExp, v.SetString(L"^A[^]*D$"));
...
delete peopleObjs;graph = sess.get_graph()
v = sparksee.Value()
...
# retrieve all 'people' node objects having a value for the 'name' attribute
# satisfying the the '^A[^]*D$' regular expression
people_objs = graph.select(name_attr_id, sparksee.Condition.REG_EXP, v.set_string("^A[^]*D$"))
...
people_objs.close()STSGraph *graph = [sess getGraph];
STSValue *v = [[STSValue alloc] init];
...
// retrieve all 'people' node objects having a value for the 'name' attribute
// satisfying the the '^A[^]*D$' regular expression
STSObjects * peopleObjs = [graph selectWithAttrValue: nameAttrId cond: STSRegExp value: [v setString: @"^A[^]*D$"]];
...
[peopleObjs close];There are two basic set of methods for the navigation through the graph:
Both methods require the source node identifier, the edge type and the direction of navigation. The edge type restricts the edge instances to be considered for the navigation, so edge instances that do not belong to the given edge type will be ignored for the operation. And the direction restricts the direction of navigation through those edges. The EdgesDirection enum class defines the following directions:
Outgoing: Only out-going edges, starting from the source node, will be valid for the navigation.Ingoing: Only in-going edges will be valid for the navigation.Any: Both out-going and in-going edges will be valid for the navigation.Note that in case of undirected edges the direction restriction has no effect as we may consider undirected edges as bidirectional edges, which do not have a restriction on the direction of the navigation.
Although both methods return an Objects instance as a result, for explode the resulting Objects instance contains edge identifiers whereas for neighbors it contains node identifiers.
The following examples show the navigational methods in use, assuming a database where PEOPLE nodes are related by means of undirected FRIEND edges and directed LOVES edges:
Graph graph = sess.getGraph();
...
long node = ... // a PEOPLE node has been retrieved somehow
int friendTypeId = graph.findType("FRIEND");
int lovesTypeId = graph.findType("LOVES");
...
// retrieve all in-comming LOVES edges
Objects edges = graph.explode(node, lovesTypeId, EdgesDirection.Ingoing);
...
// retrieve all nodes through FRIEND edges
Objects friends = graph.neighbors(node, friendTypeId, EdgesDirection.Any);
...
edges.close();
friends.close();Graph graph = sess.GetGraph();
...
long node = ... // a PEOPLE node has been retrieved somehow
int friendTypeId = graph.FindType("FRIEND");
int lovesTypeId = graph.FindType("LOVES");
...
// retrieve all in-comming LOVES edges
Objects edges = graph.Explode(node, lovesTypeId, EdgesDirection.Ingoing);
...
// retrieve all nodes through FRIEND edges
Objects friends = graph.Neighbors(node, friendTypeId, EdgesDirection.Any);
...
edges.Close();
friends.Close();Graph * graph = sess->GetGraph();
...
oid_t node = ... // a PEOPLE node has been retrieved somehow
type_t friendTypeId = graph->FindType(L"FRIEND");
type_t lovesTypeId = graph->FindType(L"LOVES");
...
// retrieve all in-comming LOVES edges
Objects * edges = graph->Explode(node, lovesTypeId, Ingoing);
...
// retrieve all nodes through FRIEND edges
Objects * friends = graph->Neighbors(node, friendTypeId, Any);
...
delete edges;
delete friends;graph = sess.get_graph()
...
node = ... # a PEOPLE node has been retrieved somehow
friend_type_id = graph.find_type(u"FRIEND")
loves_type_id = graph.find_type(u"LOVES")
...
# retrieve all in-comming LOVES edges
edges = graph.explode(node, loves_type_id, sparksee.EdgesDirection.INGOING)
...
# retrieve all nodes through FRIEND edges
friends = graph.neighbors(node, friend_type_id, sparksee.EdgesDirection.ANY)
...
edges.close()
friends.close()STSGraph *graph = [sess getGraph];
...
long long node = ...; // a PEOPLE node has been retrieved somehow
int friendTypeId = [graph findType: @"FRIEND"];
int lovesTypeId = [graph findType: @"LOVES"];
...
// retrieve all in-comming LOVES edges
STSObjects * edges = [graph explode: node etype: lovesTypeId dir: STSIngoing];
...
// retrieve all nodes through FRIEND edges
STSObjects * friends = [graph neighbors: node etype: friendTypeId dir: STSAny];
...
[edges close];
[friends close];Note that in the previous examples we have performed the neighbors call setting Any as the direction because FRIEND is an undirected relationship. In fact, any other direction (Ingoing or Outgoing) would have retrieved the same result.
For both navigation methods there is a more general implementation where instead of having a source node identifier as the first argument, there is an Objects instance. This Objects instance is the collection of object identifiers to perform the operation. The result will be an Objects instance with the union of all the results of performing the operation for each of the objects in the argument instance.
The following examples show how to use this alternative version of the neighbors method to perform a friend-of-a-friend query:
Graph graph = sess.getGraph();
...
long node = ... // a PEOPLE node has been retrieved somehow
int friendTypeId = graph.findType("FRIEND");
...
// 1-hop friends
Objects friends = graph.neighbors(node, friendTypeId, EdgesDirection.Any);
// friends of friends (2-hop)
Objects friends2 = graph.neighbors(friends, friendTypeId, EdgesDirection.Any);
...
friends.close();
friends2.close();Graph graph = sess.GetGraph();
...
long node = ... // a PEOPLE node has been retrieved somehow
int friendTypeId = graph.FindType("FRIEND");
...
// 1-hop friends
Objects friends = graph.Neighbors(node, friendTypeId, EdgesDirection.Any);
// friends of friends (2-hop)
Objects friends2 = graph.Neighbors(friends, friendTypeId, EdgesDirection.Any);
...
friends.Close();
friends2.Close();Graph * graph = sess->GetGraph();
...
oid_t node = ... // a PEOPLE node has been retrieved somehow
type_t friendTypeId = graph->FindType(L"FRIEND");
...
// 1-hop friends
Objects * friends = graph->Neighbors(node, friendTypeId, Any);
// friends of friends (2-hop)
Objects * friends2 = graph->Neighbors(friends, friendTypeId, Any);
...
delete friends;
delete friends2;graph = sess.get_graph()
...
node = ... # a PEOPLE node has been retrieved somehow
friend_type_id = graph.find_type(u"FRIEND")
...
# 1-hop friends
friends = graph.neighbors(node, friend_type_id, sparksee.EdgesDirection.ANY)
# friends of friends (2-hop)
friends2 = graph.neighbors(friends, friend_type_id, sparksee.EdgesDirection.ANY)
...
friends.close()
friends2.close()STSGraph *graph = [sess getGraph];
...
long long node = ...; // a PEOPLE node has been retrieved somehow
int friendTypeId = [graph findType: @"FRIEND"];
...
// 1-hop friends
STSObjects * friends = [graph neighbors: node etype: friendTypeId dir: STSAny];
// friends of friends (2-hop)
STSObjects * friends2 = [graph neighborsWithObjects: friends etype: friendTypeId dir: STSAny];
...
[friends close];
[friends2 close];Actually, by default the neighbors method is solved internally by performing an explode-based implementation, firstly visiting the edges themselves and then visiting the other side of the edge. Additionally a specific index may be created to improve the performance of the neighbors query. More details are in the ‘Indexing’ section of the ‘Graph database’ chapter.
This index can be set when creating an edge type (Graph#newEdgeType). Using the index, all neighbors-based operations involving that edge type will be internally performed faster. As expected, the management of an index introduces a small penalty when creating new edge instances. Nevertheless, it is strongly recommended to set an index for those applications making intensive use or critical use of the neighbors method, as the small penalty is more than compensated for the improvement in performance.
The ‘Processing’ section in the ‘Graph database’ chapter explains the execution model and Sparksee transactions in detail.
To make explicit use of transactions, the Session class provides three methods:
begin - which starts a transaction.
The transaction starts as a read transaction and will become a write transaction when:
beginUpdate - starts directly as a write transaction
commit - which ends a transaction.
rollback - which ends the transaction aborting all the changes enclosed in the transaction.
Take in to accunt that the rollback mechanism can be disabled to improve the performance when there is not any active transaction. The following example shows how to enable and disable the rollback.
SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.setClientId("Your client identifier");
cfg.setLicenseId("Your license identifier");
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.create("HelloSparksee.gdb", "HelloSparksee");
db.disableRollback(); // Rollback is now disabled
Session sess = db.newSession();
Graph graph = sess.getGraph();
//Use 'graph' to perform operations on the graph database without rollbacks
db.enableRollback(); // Rollback is now enabled
//Use 'graph' to perform operations on the graph database
sess.close();
db.close();
sparksee.close();SparkseeConfig cfg = new SparkseeConfig("sparksee.cfg");
cfg.SetClientId("Your client identifier");
cfg.SetLicenseId("Your license identifier");
Sparksee sparksee = new Sparksee(cfg);
Database db = sparksee.Create("HelloSparksee.gdb", "HelloSparksee");
db.disableRollback(); // Rollback is now disabled
Session sess = db.NewSession();
Graph graph = sess.GetGraph();
//Use 'graph' to perform operations on the graph database without rollbacks
db.EnableRollback(); // Rollback is now enabled
//Use 'graph' to perform operations on the graph database
sess.Close();
db.Close();
sparksee.Close();SparkseeConfig cfg(L"sparksee.cfg");
cfg.SetClientId(L"Your client identifier");
cfg.SetLicenseId(L"Your license identifier");
Sparksee *sparksee = new Sparksee(cfg);
Database * db = sparksee->Create(L"HelloSparksee.gdb", L"HelloSparksee");
db->DisableRollback(); // Rollback is now disabled
Session * sess = db->NewSession();
Graph * graph = sess->GetGraph();
//Use 'graph' to perform operations on the graph database without rollbacks
db->EnableRollback(); // Rollback is now enabled
//Use 'graph' to perform operations on the graph database
delete sess;
delete db;
delete sparksee;
return EXIT_SUCCESS;cfg = sparksee.SparkseeConfig("sparksee.cfg")
cfg.set_client_id("Your client identifier")
cfg.set_license_id("Your license identifier")
sparks = sparksee.Sparksee(cfg)
db = sparks.create(u"Hellosparks.gdb", u"HelloSparksee")
db.disable_rollback() # Rollback is now disabled
sess = db.new_session()
graph = sess.get_graph()
# Use 'graph' to perform operations on the graph database without rollbacks
db.enable_ollback(); # Rollback is now enabled
# Use 'graph' to perform operations on the graph database
sess.close()
db.close()
sparks.close()STSSparkseeConfig *cfg = [[STSSparkseeConfig alloc] initWithPath: @"sparksee.cfg"];
[cfg setClientId: @"Your client identifier"];
[cfg setLicenseId: @"Your license identifier"];
STSSparksee *sparksee = [[STSSparksee alloc] initWithConfig: cfg];
// If you are not using Objective-C Automatic Reference Counting , you
// may want to release the cfg here, when it's no longer needed.
//[cfg release];
STSDatabase *db = [sparksee create: @"HelloSparksee.gdb" alias: @"HelloSparksee"];
[db disableRollback]; // Rollback is now disabled
STSSession *sess = [db createSession];
STSGraph *graph = [sess getGraph];
//Use 'graph' to perform operations on the graph database without rollbacks
[db enableRollback]; // Rollback is now enabled
//Use 'graph' to perform operations on the graph database
[sess close];
[db close];
[sparksee close];
// If you are not using Objective-C Automatic Reference Counting , you
// may want to release the sparksee here , when it's closed.
//[sparksee release];The following examples illustrate the fomer explained behavior when a transaction starts as a read transaction but when the first write method (in this case, the newNode method) is executed, it becomes a write transaction:
Value v = new Value();
sess.begin(); // Start a Transaction as a read transaction
int peopleTypeId = graph.findType("PEOPLE");
int nameAttrId = graph.findAttribute(peopleTypeId, "NAME");
// In the following newNode method the transaction becomes a write transaction
long billMurray = graph.newNode(peopleTypeId);
graph.setAttribute(billMurray, nameAttrId, v.setString("Bill Murray"));
// Create a birth year attribute
int birthYearAttrId = graph.newAttribute(peopleTypeId, "BIRTH YEAR", DataType.Integer, AttributeKind.Basic);
// Set Bill Murray's birth year
graph.setAttribute(billMurray, birthYearAttrId, v.setInteger(1950));
// Commit all the changes
sess.commit();
...
// Start a new transaction to change the birth year of Bill Murray
sess.begin();
graph.setAttribute(billMurray, birthYearAttrId, v.setInteger(2050));
// That change was a mistake, so use the rollback method
sess.rollback();
...
// Check that the attribute is still 1950
// We don't use a transaction, so the next method is in autocommit
graph.getAttribute(billMurray, birthYearAttrId, v);
Assert(v.getInteger() == 1950);Value v = new Value();
sess.Begin(); // Start a Transaction as a read transaction
int peopleTypeId = graph.FindType("PEOPLE");
int nameAttrId = graph.FindAttribute(peopleTypeId, "NAME");
// In the following NewNode method the transaction becomes a write transaction
long billMurray = graph.NewNode(peopleTypeId);
graph.SetAttribute(billMurray, nameAttrId, v.SetString("Bill Murray"));
// Create a birth year attribute
int birthYearAttrId = graph.NewAttribute(peopleTypeId, "BIRTH YEAR", DataType.Integer, AttributeKind.Basic);
// Set Bill Murray's birth year
graph.SetAttribute(billMurray, birthYearAttrId, v.SetInteger(1950));
// Commit all the changes
sess.Commit();
...
// Start a new transaction to change the birth year of Bill Murray
sess.Begin();
graph.SetAttribute(billMurray, birthYearAttrId, v.SetInteger(2050));
// That change was a mistake, so use the rollback method
sess.Rollback();
...
// Check that the attribute is still 1950
// We don't use a transaction, so the next method is in autocommit
graph.GetAttribute(billMurray, birthYearAttrId, v);
Assert(v.GetInteger() == 1950);Value v;
sess->Begin(); // Start a Transaction as a read transaction
type_t peopleTypeId = graph->FindType(L"PEOPLE");
attr_t nameAttrId = graph->FindAttribute(peopleTypeId, L"NAME");
// In the following NewNode method the transaction becomes a write transaction
oid_t billMurray = graph->NewNode(peopleTypeId);
graph->SetAttribute(billMurray, nameAttrId, v.SetString(L"Bill Murray"));
// Create a birth year attribute
int birthYearAttrId = graph->NewAttribute(peopleTypeId, L"BIRTH YEAR", Integer, Basic);
// Set Bill Murray's birth year
graph->SetAttribute(billMurray, birthYearAttrId, v.SetInteger(1950));
// Commit all the changes
sess->Commit();
...
// Start a new transaction to change the birth year of Bill Murray
sess->Begin();
graph->SetAttribute(billMurray, birthYearAttrId, v.SetInteger(2050));
// That change was a mistake, so use the rollback method
sess->Rollback();
...
// Check that the attribute is still 1950
// We don't use a transaction, so the next method is in autocommit
graph->GetAttribute(billMurray, birthYearAttrId, v);
assert(v.GetInteger() == 1950);v = sparksee.Value()
sess.begin() # Start a Transaction as a read transaction
peopleTypeId == graph.find_type("PEOPLE")
nameAttrId = graph.find_attribute(peopleTypeId, "NAME")
# In the following new_node method the transaction becomes a write transaction
billMurray = graph.new_node(peopleTypeId)
graph.set_attribute(billMurray, nameAttrId, v.set_string("Bill Murray"))
# Create a birth year attribute
birthYearAttrId = graph.new_attribute(peopleTypeId, "BIRTH YEAR", sparksee.DataType.INTEGER, sparksee.AttributeKind.BASIC);
# Set Bill Murray's birth year
graph.set_attribute(billMurray, birthYearAttrId, v.set_integer(1950));
# Commit all the changes
sess.commit()
...
# Start a new transaction to change the birth year of Bill Murray
sess.begin()
graph.set_attribute(billMurray, birthYearAttrId, v.set_integer(2050));
# That change was a mistake, so use the rollback method
sess.rollback();
...
# Check that the attribute is still 1950
# We don't use a transaction, so the next method is in autocommit
graph.get_attribute(billMurray, birthYearAttrId, v);
assert(v.get_integer() == 1950);STSValue *v = [[STSValue alloc] init];
[sess begin]; // Start a Transaction as a read transaction
int peopleTypeId = [graph findType: @"PEOPLE"];
int nameAttrId = [graph findAttribute: peopleTypeId name: @"NAME"];
[v setString: @"Bill Murray"];
// In the following createNode method the transaction becomes a write transaction
long long billMurray = [graph createNode: peopleTypeId];
[graph setAttribute: billMurray attr: nameAttrId value: v];
// Create a birth year attribute
int birthYearAttrId = [graph createAttribute: peopleTypeId name: @"BIRTH YEAR" dt: STSInteger kind: STSBasic];
// Set Bill Murray's birth year
[graph setAttribute: billMurray attr: birthYearAttrId value: [v setInteger: 1950]];
// Commit all the changes
[sess commit];
...
// Start a new transaction to change the birth year of Bill Murray
[sess begin];
[graph setAttribute: billMurray attr: birthYearAttrId value: [v setInteger: 2050]];
// That change was a mistake, so use the rollback method
[sess rollback];
...
// Check that the attribute is still 1950
// We don't use a transaction, so the next method is in autocommit
[graph getAttributeInValue: billMurray attr: birthYearAttrId value: v];
assert([v getInteger] == 1950);Note that the previous codes are also valid without the begin/commit calls because they are automatically executed in autocommit mode, where a transaction is created for each one of the calls.
Sparksee provides utilities to export a graph into visual format or import/export data from external data sources.
Data stored in a Sparksee graph database can be exported to a visual-oriented representation format.
The available visual exports formats for Sparksee are defined in the ExportType class:
this is an open-source graph visualization software. The Graphviz layouts take descriptions of graphs in a text language and make diagrams in useful formats, such as images and SVG for web pages or PDF and Postscript for inclusion in other documents. The resulting formats can also be displayed in an interactive graph browser (also supports GXL, an XML dialect). Graphviz has many useful features to personalize the diagrams, such as options for colors, fonts, tabular node layouts, line styles, hyperlinks and rolland custom shapes.
GraphML is a file format for graphs based on XML, so it is especially suitable as a common denominator for all kinds of services that generate, archive, or process graphs. This is the reason it is considered a standard for graph exportation. Its core language describes the structural properties of a graph while the extensions add application-specific data. Its main features include support of directed, undirected, and mixed graphs, hypergraphs, hierarchical graphs, graphical representations, references to external data, application-specific attribute data, and light-weight parsers.
YGraphML
YGraphML is a format based in GraphML that has some exclusive extensions for yEd Graph Editor. yED is a desktop application that can be used to generate graphs or diagrams which can be browsed with the application and then imported or exported to different data formats.
Sparksee includes the method Graph#export to export the stored data in any of the previously explained formats. The method has the following parameters:
ExportManager class.The ExportManager class defines the properties to be exported in the following classes:
GraphExport: a global label can be defined for the graph.NodeExport: label, label color, color, shape, width, font, font size, as well as other properties can be set for a node.EdgeExport: label, label color, width, font, font size, arrows, as well as other properties can be set for an edge.Note that only some of these properties are meaningful for some of the available export type formats.
The DefaultExport is an implementation of the ExportManager class already provided in the Sparksee library which performs a default exportation of the settings for the whole database. Examples of a default exportation:
Graph graph = sess.getGraph();
...
ExportManager expMngr = new DefaultExport();
graph.export("test.dot", ExportType.Graphviz, expMngr);Graph graph = sess.GetGraph();
...
ExportManager expMngr = new DefaultExport();
graph.Export("test.dot", ExportType.Graphviz, expMngr);Graph * graph = sess->GetGraph();
...
ExportManager * expMngr = new DefaultExport();
graph->Export(L"test.dot", Graphviz, expMngr);
delete expMngr;graph = sess.get_graph()
...
expMngr = sparksee.DefaultExport()
graph.export("test.dot", sparksee.ExportType.GRAPHVIZ, expMngr)STSGraph *graph = [sess getGraph];
...
STSExportManager *expMngr = [[STSDefaultExport alloc] init];
[graph exportGraph: @"test.dot" type: STSGraphviz em: expMngr];
//[expMngr release];The ExportManager class contains the following methods:
getNodeType: the user can set the properties to export all nodes belonging to a given type by setting the NodeExport in/out parameter.getNode: the user can override the previous NodeExport definition for the specific given node instance.getEdgeType: the same as getNodeType but for edge types.getEdge: the same as getNode but for edge instances.enableType: the user can skip a whole node or edge type from the export process.getGraph: the user can set certain global properties for the graph.prepare: this is called when the export process starts.release: this is called when the export process ends (the method name is close in Objective-C).The following codes are an example of how to export the graph from Figure-2.1 using the previously explained methods from the ExportManager class:
import com.sparsity.sparksee.gdb.*;
public class MyExport extends ExportManager {
private Graph g = null;
private int peopleTypeId = Type.InvalidType;
private int nameAttrId = Attribute.InvalidAttribute;
private int moviesTypeId = Type.InvalidType;
private int titleAttrId = Attribute.InvalidAttribute;
private int castTypeId = Type.InvalidType;
private int directsTypeId = Type.InvalidType;
private Value v = new Value();
@Override
public void prepare(Graph graph) {
g = graph;
peopleTypeId = g.findType("PEOPLE");
nameAttrId = g.findAttribute(peopleTypeId, "Name");
moviesTypeId = g.findType("MOVIES");
titleAttrId = g.findAttribute(moviesTypeId, "Title");
castTypeId = g.findType("CAST");
directsTypeId = g.findType("DIRECTS");
}
@Override
public void release() {
}
@Override
public boolean getGraph(GraphExport ge) {
ge.setLabel("Hollywood");
return true;
}
@Override
public boolean getNodeType(int nodetype, NodeExport ne) {
// default node type export:
// - PEOPLE in RED nodes
// - MOVIES in ORANGE nodes
if (nodetype == peopleTypeId) {
ne.setColor(java.awt.Color.RED);
} else if (nodetype == moviesTypeId) {
ne.setColor(java.awt.Color.ORANGE);
} else {
assert false;
}
return true;
}
@Override
public boolean getEdgeType(int edgetype, EdgeExport ee) {
// default edge type export:
// - CAST in YELLOW lines
// - DIRECTS in BLUE lines
if (edgetype == castTypeId) {
ee.setColor(java.awt.Color.YELLOW);
} else if (edgetype == directsTypeId) {
ee.setColor(java.awt.Color.BLUE);
} else {
assert false;
}
return true;
}
@Override
public boolean getNode(long nodeOID, NodeExport ne) {
// specific node export:
// - PEOPLE: use the Name attribute as label
// - MOVIES: use the Title attribute as label
int nodetype = g.getObjectType(nodeOID);
if (nodetype == peopleTypeId) {
g.getAttribute(nodeOID, nameAttrId, v);
} else if (nodetype == moviesTypeId) {
g.getAttribute(nodeOID, titleAttrId, v);
} else {
assert false;
}
ne.setLabel("[" + nodeOID + "]" + v.toString());
return true;
}
@Override
public boolean getEdge(long edgeOID, EdgeExport ee) {
// default edge type export is enough
return false;
}
@Override
public boolean enableType(int type) {
// enable all node and edge types
return true;
}
}using com.sparsity.sparksee.gdb.*;
public class MyExport : ExportManager {
private Graph g = null;
private int peopleTypeId = Type.InvalidType;
private int nameAttrId = Attribute.InvalidAttribute;
private int moviesTypeId = Type.InvalidType;
private int titleAttrId = Attribute.InvalidAttribute;
private int castTypeId = Type.InvalidType;
private int directsTypeId = Type.InvalidType;
private Value v = new Value();
public override void Prepare(Graph graph) {
g = graph;
peopleTypeId = g.FindType("PEOPLE");
nameAttrId = g.FindAttribute(peopleTypeId, "Name");
moviesTypeId = g.FindType("MOVIES");
titleAttrId = g.FindAttribute(moviesTypeId, "Title");
castTypeId = g.FindType("CAST");
directsTypeId = g.FindType("DIRECTS");
}
public override void Release() {
}
public override bool GetGraph(GraphExport ge) {
ge.SetLabel("Hollywood");
return true;
}
public override bool GetNodeType(int nodetype, NodeExport ne) {
// default node type export:
// - PEOPLE in RED nodes
// - MOVIES in ORANGE nodes
if (nodetype == peopleTypeId) {
ne.SetColor(System.Drawing.Color.Red);
} else if (nodetype == moviesTypeId) {
ne.SetColor(System.Drawing.Color.Orange);
} else {
System.Diagnostics.Debug.Assert(false);
}
return true;
}
public override bool GetEdgeType(int edgetype, EdgeExport ee) {
// default edge type export:
// - CAST in YELLOW lines
// - DIRECTS in BLUE lines
if (edgetype == castTypeId) {
ee.SetColor(System.Drawing.Color.Yellow);
} else if (edgetype == directsTypeId) {
ee.SetColor(System.Drawing.Color.Blue);
} else {
System.Diagnostics.Debug.Assert(false);
}
return true;
}
public override bool GetNode(long nodeOID, NodeExport ne) {
// specific node export:
// - PEOPLE: use the Name attribute as label
// - MOVIES: use the Title attribute as label
int nodetype = g.GetObjectType(nodeOID);
if (nodetype == peopleTypeId) {
g.GetAttribute(nodeOID, nameAttrId, v);
} else if (nodetype == moviesTypeId) {
g.GetAttribute(nodeOID, titleAttrId, v);
} else {
System.Diagnostics.Debug.Assert(false);
}
ne.SetLabel("[" + nodeOID + "]" + v.ToString());
return true;
}
public override bool GetEdge(long edgeOID, EdgeExport ee) {
// default edge type export is enough
return false;
}
public override bool EnableType(int type) {
// enable all node and edge types
return true;
}
}#include <stdio.h>
#include "gdb/Sparksee.h"
#include "gdb/Database.h"
#include "gdb/Session.h"
#include "gdb/Graph.h"
#include "gdb/Objects.h"
#include "gdb/ObjectsIterator.h"
#include "gdb/Stream.h"
#include "gdb/Export.h"
#include <assert.h>
using namespace sparksee::gdb;
class MyExport : ExportManager {
private:
Graph * g;
type_t peopleTypeId;
attr_t nameAttrId;
type_t moviesTypeId;
attr_t titleAttrId;
type_t castTypeId;
type_t directsTypeId;
Value v;
public:
MyExport()
: g(NULL)
, peopleTypeId(Type::InvalidType)
, nameAttrId(Attribute::InvalidAttribute)
, moviesTypeId(Type::InvalidType)
, titleAttrId(Attribute::InvalidAttribute)
, castTypeId(Type::InvalidType)
, directsTypeId(Type::InvalidType) {
}
virtual void Prepare(Graph * graph) {
g = graph;
peopleTypeId = g->FindType(L"PEOPLE");
nameAttrId = g->FindAttribute(peopleTypeId, L"Name");
moviesTypeId = g->FindType(L"MOVIES");
titleAttrId = g->FindAttribute(moviesTypeId, L"Title");
castTypeId = g->FindType(L"CAST");
directsTypeId = g->FindType(L"DIRECTS");
}
virtual void Release() {
}
virtual bool GetGraph(GraphExport * ge) {
ge->SetLabel(L"Hollywood");
return true;
}
virtual bool GetNodeType(int nodetype, NodeExport * ne) {
// default node type export:
// - PEOPLE in RED nodes
// - MOVIES in ORANGE nodes
if (nodetype == peopleTypeId) {
ne->SetColorRGB(16711680); // red
} else if (nodetype == moviesTypeId) {
ne->SetColorRGB(16744192); // ORANGE
} else {
assert(false);
}
return true;
}
virtual bool GetEdgeType(int edgetype, EdgeExport * ee) {
// default edge type export:
// - CAST in YELLOW lines
// - DIRECTS in BLUE lines
if (edgetype == castTypeId) {
ee->SetColorRGB(16776960); // yellow
} else if (edgetype == directsTypeId) {
ee->SetColorRGB(255); // blue
} else {
assert(false);
}
return true;
}
virtual bool GetNode(long nodeOID, NodeExport * ne) {
// specific node export:
// - PEOPLE: use the Name attribute as label
// - MOVIES: use the Title attribute as label
int nodetype = g->GetObjectType(nodeOID);
if (nodetype == peopleTypeId) {
g->GetAttribute(nodeOID, nameAttrId, v);
} else if (nodetype == moviesTypeId) {
g->GetAttribute(nodeOID, titleAttrId, v);
} else {
assert(false);
}
std::wstring aux2;
std::wstringstream aux;
aux << L"[" << nodeOID << L"]" << v.ToString(aux2);
ne->SetLabel(aux.str());
return true;
}
virtual bool GetEdge(long edgeOID, EdgeExport * ee) {
// default edge type export is enough
return false;
}
virtual bool EnableType(int type) {
// enable all node and edge types
return true;
}
};import sparksee
class MyExport(sparksee.ExportManager):
def __init__(self):
sparksee.ExportManager.__init__(self)
def prepare(self, g):
self.graph = g;
self.people_type_id = self.graph.find_type(u"PEOPLE")
self.name_attribute_id = self.graph.find_attribute(self.people_type_id, u"Name")
self.movies_type_id = self.graph.find_type(u"MOVIES")
self.title_attribute_id = self.graph.find_attribute(self.movies_type_id, u"Title")
self.cast_type_id = self.graph.find_type(u"CAST")
self.directs_type_id = self.graph.find_type(u"DIRECTS")
def release(self):
self.graph = None
def get_graph(self, graphExport):
graphExport.set_label("Hollywood")
return True
def get_node_type(self, node_type, nodeExport):
# default node type export:
# - PEOPLE in RED nodes
# - MOVIES in ORANGE nodes
if node_type == self.people_type_id:
nodeExport.set_color_rgb(16711680)
elif node_type == self.movies_type_id:
nodeExport.set_color_rgb(65535)
else:
assert False
return True
def get_edge_type(self, edge_type, edgeExport):
# default edge type export:
# - CAST in YELLOW lines
# - DIRECTS in BLUE lines
if edge_type == self.cast_type_id:
edgeExport.set_color_rgb(16776960)
elif edge_type == self.directs_type_id:
edgeExport.set_color_rgb(255)
else:
assert False
return True
def get_node(self, node_oid, nodeExport):
# specific node export:
# - PEOPLE: use the Name attribute as label
# - MOVIES: use the Title attribute as label
v = sparksee.Value()
node_type = self.graph.get_object_type(node_oid)
if node_type == self.people_type_id:
self.graph.get_attribute(node_oid, self.name_attribute_id, v)
elif node_type == self.movies_type_id:
self.graph.get_attribute(node_oid, self.title_attribute_id, v)
else:
assert False
nodeExport.set_label(u"[" + str(node_oid) + u"]" + v.get_string())
return True
def get_edge(self, edge, edgeExport):
# default edge type export is enough
return False
def enable_type(self, my_type):
# enable all node and edge types
return True#import <Sparksee/Sparksee.h>
@interface MyExport : STSExportManager
{
STSGraph *g;
int peopleTypeId;
int nameAttrId;
int moviesTypeId;
int titleAttrId;
int castTypeId;
int directsTypeId;
STSValue *value;
}
-(id)init;
-(void)prepare: (STSGraph*)graph;
-(void)close;
-(BOOL)getGraph: (STSGraphExport*)graphExport;
-(BOOL)getNodeType: (int)type nodeExport: (STSNodeExport*)nodeExport;
-(BOOL)getEdgeType: (int)type edgeExport: (STSEdgeExport*)edgeExport;
-(BOOL)getNode: (long long)node nodeExport: (STSNodeExport*)nodeExport;
-(BOOL)getEdge: (long long)edge edgeExport: (STSEdgeExport*)edgeExport;
-(BOOL)enableType: (int)type;
@end
@implementation MyExport
- (id)init
{
self = [super init];
return self;
}
-(void)prepare: (STSGraph*)graph
{
g = graph;
peopleTypeId = [g findType: @"PEOPLE"];
nameAttrId = [g findAttribute: peopleTypeId name: @"Name"];
moviesTypeId = [g findType: @"MOVIES"];
titleAttrId = [g findAttribute: moviesTypeId name: @"Title"];
castTypeId = [g findType: @"CAST"];
directsTypeId = [g findType: @"DIRECTS"];
value = [[STSValue alloc] init];
}
-(void)close
{
g = NULL;
//[value release];
}
-(BOOL)getGraph: (STSGraphExport*)graphExport
{
[graphExport setLabel: @"Hollywood"];
return TRUE;
}
-(BOOL)getNodeType: (int)type nodeExport: (STSNodeExport*)nodeExport
{
// default node type export:
// - PEOPLE in RED nodes
// - MOVIES in ORANGE nodes
if (type == peopleTypeId) {
[nodeExport setColorRGB: 16711680]; // red == 0xFFFF00
} else if (type == moviesTypeId) {
[nodeExport setColorRGB: 0xFF7F00]; // ORANGE == 16744192
} else {
NSLog(@"Unknown type");
}
return TRUE;
}
-(BOOL)getEdgeType: (int)type edgeExport: (STSEdgeExport*)edgeExport
{
// default edge type export:
// - CAST in YELLOW lines
// - DIRECTS in BLUE lines
if (type == castTypeId) {
[edgeExport setColorRed: 1.0 green: 1.0 blue: 0.0 alpha: 0.0]; // yellow == 16776960
} else if (type == directsTypeId) {
[edgeExport setColorRGB: 255]; // blue
} else {
NSLog(@"Unknown type");
}
return TRUE;
}
-(BOOL)getNode: (long long)node nodeExport: (STSNodeExport*)nodeExport
{
// specific node export:
// - PEOPLE: use the Name attribute as label
// - MOVIES: use the Title attribute as label
int nodetype = [g getObjectType: node];
if (nodetype == peopleTypeId) {
[g getAttributeInValue: node attr: nameAttrId value: value];
} else if (nodetype == moviesTypeId) {
[g getAttributeInValue: node attr: titleAttrId value: value];
} else {
NSLog(@"Unknown type");
}
[nodeExport setLabel: [NSString stringWithFormat: @"[%lld]%@", node, [value getString]]];
return TRUE;
}
-(BOOL)getEdge: (long long)edge edgeExport: (STSEdgeExport*)edgeExport
{
// default edge type export is enough
return FALSE;
}
-(BOOL)enableType: (int)type
{
// enable all node and edge types
return TRUE;
}
@endInstead of manually creating node and edge objects, data can be imported following a certain schema, in bulk.
This functionality is provided by classes in the com.sparsity.sparksee.io package for Sparkseejava, the com.sparsity.sparksee.io namespace for Sparkseenet, and in the sparksee::io namespace in Sparkseecpp. We provide two utilities to help loading data to sparksee in a bulk manner: The CSVLoader, the RowReader and TypeLoader.
The CSVLoader is an API built on top of the RowReader to facilitate the loading of graphs from CSVs. The CSVLoader provides two methods: CSVLoader#loadeNodes and CSVLoader#loadEdges (in Python, these are called load_nodes_csv and load_edges_csv). Both methods allow loading nodes and edges respectively from CSV files, as well as their associated attributes. Additionally, they allow to specify the following:
The name of the object where the data have to be loaded
The subset of columns to load
The separator character
In the case of CSVLoader#loadEdges, also the type of the endpoints, as well as the policy to follow when the endpoints do not exist (e.g. throw an error, ignore the edge or create the endpoints) and the edge direction
The attribute names or inferring them from the header (if this exist)
The attribute data types or inferring them from the first row
The attribute kinds
For instance, assume the following small social network
NAME; NAME; TYPE
name1; name2; family
name1; name3; family
name2; name4; friend
name2; name5; coworker
name3; name4; friendCSVLoader.loadEdges(g,
"social_network.csv", // path to csv file
"friendship", // edge type name
"person", // tail type name
"person", // head type name
0, // tail column
1, // head column
";", // separator
true, // direction
true, // has header
MissingEndpoint.Create, // tail's missing endpoint policy
MissingEndpoint.Create, // head's missing endpoint policy
new int[]{0,1,2}, // columns to load
new String[]{"name", // attribute type names to create
"name",
"type"},
new DataType[]{DataType.String, // attribute data types
DataType.String,
DataType.String,
},
new AttributeKind[]{AttributeKind.Indexed,// attribute kinds
AttributeKind.Indexed,
AttributeKind.Basic});CSVLoader.LoadEdges(g,
"social_network.csv", // path to csv file
"friendship", // edge type name
"person", // tail type name
"person", // head type name
0, // tail column
1, // head column
";", // separator
true, // direction
true, // has header
MissingEndpoint.Create, // tail's missing endpoint policy
MissingEndpoint.Create, // head's missing endpoint policy
new int[]{0,1,2}, // columns to load
new string[]{"name", // attribute type names to create
"name",
"type"},
new DataType[]{DataType.String, // attribute data types to create
DataType.String,
DataType.String,
},
new AttributeKind[]{AttributeKind.Indexed,// attribute kinds to create
AttributeKind.Indexed,
AttributeKind.Basic});std::vector<int32_t> columns;
columns.push_back(0);
columns.push_back(1);
columns.push_back(2);
std::vector<std::wstring> attrNames;
attrNames.push_back(L"name");
attrNames.push_back(L"name");
attrNames.push_back(L"type");
std::vector<DataType> dataTypes;
dataTypes.push_back(String)
dataTypes.push_back(String)
dataTypes.push_back(String)
std::vector<AttributeKind> attrKinds;
attrKinds.push_back(Indexed);
attrKinds.push_back(Indexed);
attrKinds.push_back(Basic);
CSVLoader.LoadEdges(g,
L"social_network.csv", // path to csv file
L"friendship", // edge type name
L"person", // tail type name
L"person", // head type name
0, // tail column
1, // head column
L";", // separator
true, // direction
true, // has header
Create, // tail's missing endpoint policy
Create, // head's missing endpoint policy
columns, // columns to load
attrNames, // attribute type names to create
dataTypes, // attribute data types to create
attrKinds); // attribute kinds to createsparksee.load_edges_csv(g,
"social_network.csv", // path to csv file
"friendship", // edge type name
"person", // tail type name
"person", // head type name
tail = 0, // tail column
head = 1, // head column
separator = ";", // separator
directed = True, // direction
header = True, // has header
on_missing_tail = sparksee.MissingEndpoint.CREATE,// tail's missing endpoint policy
on_missing_head = sparksee.MissingEndpoint.CREATE,// head's missing endpoint policy
columns = [0, 1, 2], // columns to load
attr_names = ["name", "name", "type"], // attribute type names to create
data_types = [sparksee.DataType.STRING
sparksee.DataType.STRING,
sparksee.DataType.STRING], // attribute data types to create
attrKinds = [sparksee.AttributeKind.INDEXED,
sparksee.AttributeKind.INDEXED,
sparksee.AttributeKind.BASIC]) // attribute kinds to create[STSCSVLoader loadEdges: g,
fileName: @"social_network.csv", // path to csv file
edgeType: @"friendship", // edge type name
tailNodeType: @"person", // tail type name
headNodeType: @"person", // head type name
tail: 0, // tail column
head: 1, // head column
separator: @";", // separator
directed: true, // direction
header: true, // has header
onMissingTail: STSCreate, // tail's missing endpoint policy
onMissingHead: STSCreate, // head's missing endpoint policy
columns: @[@0, @1, @2], // columns to load
attrNames: @[@"name", @"name", @"type"], // attribute type names to create
dataTypes: @[@(STSString),
@(STSString),
@(STSString)], // attribute data types to create
attrKinds: @[@(STSIndexed),
@(STSIndexed),
@(STSBasic)]) // attribute kinds to createIn order to facilitate the creation of loaders that behave differently than the CSVLoader provided, we offer two classes for importing data into Sparksee the RowReader and the TypeLoader. The RowReader is an interface used to read external data sources and shows this data to the user with a row-based logical format. We provide an implementation for the RowReader, called the CSVReader, to read CSV files. Users can provide their RowReader implementations supporting other formats. RowReader are used with the TypeLoader class, which is used to import data into a Sparksee graph.
The most important method defined by the RowReader is the bool RowReader#read(StringList row) method which returns true if a row has been read or false otherwise. If a row has been read, the output argument row is a list of strings, each string being a column within the row. The RowReader#close method must be called once the processing ends.
The CSVReader class extends the parent class with extra functionality:
CSVReader#open sets the path of the CSV file to be read.
Set the locale of the file by means of a case in-sensitive string argument with the following format: an optional language, a dot (‘.’) character and a coding specification.
Thus, valid locale arguments are: “en_US.UTF8”, “es_ES.ISO88591”, “.UTF8”, etc. If not specified, “en_US.iso88591” is the default locale.
Set a separator character (to limit columns) with CSVReader#setSeparator or set the quote character for strings with CSVReader#setQuotes. For quoted strings it is also possible to set a restriction for them to be single-lined or allow them to be multi-lined. In the second case the user should limit the maximum number of lines.
Finally, it is possible to skip some lines at the beginning of the file (CSVReader#setStartLine) or fix a maximum number of lines to be read (CSVReader#setNumLines).
Let’s look at an example of the use of the CSVReader class and its functionalities, for a csv such as the following:
It could be read using a CSVReader as follows:
CSVReader csv = new CSVReader();
csv.setSeparator(";");
csv.setStartLine(1);
csv.open("people.csv");
StringList row = new StringList();
while (csv.read(row))
{
System.out.println(">> Reading line num " + csv.getRow());
StringListIterator it = row.iterator();
while (it.hasNext())
{
System.out.println(it.next());
}
}
csv.close();CSVReader csv = new CSVReader();
csv.SetSeparator(";");
csv.SetStartLine(1);
csv.Open("people.csv");
StringList row = new StringList();
while (csv.Read(row))
{
System.Console.WriteLine(">> Reading line num " + csv.GetRow());
StringListIterator it = row.Iterator();
while (it.HasNext())
{
System.Console.WriteLine(it.Next());
}
}
csv.Close();CSVReader csv;
csv.SetSeparator(L";");
csv.SetStartLine(1);
csv.Open(L"people.csv");
StringList row;
while (csv.Read(row))
{
std::cout << ">> Reading line num " << csv.GetRow() << std::endl;
StringListIterator * it = row.Iterator();
while (it->HasNext())
{
std::wcout << it->Next() << std::endl;
}
delete it;
}
csv.Close();csv = sparksee.CSVReader()
csv.set_separator(u";")
csv.set_start_line(1)
csv.open(u"people.csv")
row = sparksee.StringList()
while csv.read(row):
print ">> Reading line num " + str(csv.get_row())
for elem in row:
print elem
csv.close()STSCSVReader *csv = [[STSCSVReader alloc] init];
[csv setSeparator: @";"];
[csv setStartLine: 1];
[csv open: @"people.csv"];
STSStringList *row = [[STSStringList alloc] init];
while ([csv read: row])
{
NSLog(@">> Reading line num %d\n", [csv getRow]);
STSStringListIterator * it = [row iterator];
while ([it hasNext])
{
NSLog(@"%@\n", [it next]);
}
}
[csv close];
//[csv release];
//[row release];Note that the separator and the first line to be read have been set in the first place.
There are two implementations for the TypeLoader class, regarding whether the element to be included in the graph is a node, the NodeTypeLoader class, or an edge, the EdgeTypeLoader class.
The functionality of the TypeLoader class includes:
Execution mode:
TypeLoader#run. The CSV file is read once and the objects are created in the graph.TypeLoader#runTwoPhases. The CSV file is read twice: once to create the objects and once again to set the attribute values.TypeLoader#runNPhases(int num). The CSV file is read N times: once to create the objects and then once for each attribute column. Each attribute column is logically partitioned, so the data column is loaded in num partitions.It is possible to register listeners to receive progress events from the TypeLoader (TypeLoader#register). This requires the user to implement the TypeLoaderListener class. The frequency with which these events are generated can also be configured (TypeLoader#setFrequency).
In case of parsing a string column to load a Timestamp attribute, the timestamp format can be set by the user.
Valid format fields are:
yyyy: Yearyy: Year without century interpreted. Within 80 years before or 20 years after the current year. For example, if the current year is 2007, the pattern MM/dd/yy for the value 01/11/12 parses to January 11, 2012, while the same pattern for the value 05/04/64 parses to May 4, 1964.MM: Month [1..12]dd: Day of month [1..31]hh: Hour [0..23]mm: Minute [0..59]ss: Second [0..59]SSS: Millisecond [0..999]Therefore, valid timestamp formats may be: MM/dd/yy or MM/dd/yyyy-hh.mm. If not specified, the parser automatically tries to match any of the following timestamp formats:
yyyy-MM-dd hh:mm:ss.SSSyyyy-MM-dd hh:mm:ssyyyy-MM-ddThe following examples show how to use the CSVReader and the TypeLoader classes in order to execute a basic import of the nodes “PEOPLE” that have two attributes “Name and”Age" into a graph:
Graph graph = sess.getGraph();
int peopleTypeId = graph.findType("PEOPLE");
...
// configure CSV reader
CSVReader csv = new CSVReader();
csv.setSeparator(";");
csv.setStartLine(1);
csv.open("people.csv");
// set attributes to be loaded and their positions
AttributeList attrs = new AttributeList();
Int32List attrPos = new Int32List();
// NAME attribute in the second column
attrs.add(graph.findAttribute(peopleTypeId, "Name"));
attrPos.add(1);
// AGE attribute in the fourth column
attrs.add(graph.findAttribute(peopleTypeId, "Age"));
attrPos.add(3);
// import PEOPLE node type
NodeTypeLoader ntl = new NodeTypeLoader(csv, graph, peopleTypeId, attrs, attrPos);
ntl.setLogError("people.csv.log");
ntl.run();
csv.close();Graph graph = sess.GetGraph();
int peopleTypeId = graph.FindType("PEOPLE");
...
// configure CSV reader
CSVReader csv = new CSVReader();
csv.SetSeparator(";");
csv.SetStartLine(1);
csv.Open("people.csv");
// set attributes to be loaded and their positions
AttributeList attrs = new AttributeList();
Int32List attrPos = new Int32List();
// NAME attribute in the second column
attrs.Add(graph.FindAttribute(peopleTypeId, "NAME"));
attrPos.Add(1);
// AGE attribute in the fourth column
attrs.Add(graph.FindAttribute(peopleTypeId, "AGE"));
attrPos.Add(3);
// import PEOPLE node type
NodeTypeLoader ntl = new NodeTypeLoader(csv, graph, peopleTypeId, attrs, attrPos);
ntl.SetLogError("people.csv.log");
ntl.Run();
csv.Close();Graph * graph = sess->GetGraph();
type_t peopleTypeId = graph->FindType(L"PEOPLE");
...
// configure CSV reader
CSVReader csv;
csv.SetSeparator(L";");
csv.SetStartLine(1);
csv.Open(L"people.csv");
// set attributes to be loaded and their positions
AttributeList attrs;
Int32List attrPos;
// NAME attribute in the second column
attrs.Add(graph->FindAttribute(peopleTypeId, L"NAME"));
attrPos.Add(1);
// AGE attribute in the fourth column
attrs.Add(graph->FindAttribute(peopleTypeId, L"AGE"));
attrPos.Add(3);
// import PEOPLE node type
NodeTypeLoader ntl(csv, *graph, peopleTypeId, attrs, attrPos);
ntl.SetLogError(L"people.csv.log");
ntl.Run();
csv.Close();graph = sess.get_graph()
people_type_id = graph.new_node_type(u"PEOPLE")
...
# configure CSV reader
csv = sparksee.CSVReader()
csv.set_separator(u";")
csv.set_start_line(1)
csv.open(u"people.csv")
# set attributes to be loaded and their positions
attrs = sparksee.AttributeList()
attrPos = sparksee.Int32List()
# NAME attribute in the second column
attrs.add(graph.find_attribute(people_type_id, u"Name"))
attrPos.add(1)
# AGE attribute in the fourth column
attrs.add(graph.find_attribute(people_type_id, u"Age"))
attrPos.add(3)
# import PEOPLE node type
ntl = sparksee.NodeTypeLoader(csv, graph, people_type_id, attrs, attrPos)
ntl.set_log_error(u"people.csv.log")
ntl.run()
csv.close()STSGraph *graph = [sess getGraph];
peopleTypeId = [graph findType: @"PEOPLE"];
...
// configure CSV reader
csv = [[STSCSVReader alloc] init];
[csv setSeparator: @";"];
[csv setStartLine: 1];
[csv open: @"people.csv"];
// set attributes to be loaded and their positions
STSAttributeList *attrs = [[STSAttributeList alloc] init];
STSInt32List *attrPos = [[STSInt32List alloc] init];
// NAME attribute in the second column
[attrs add: [graph findAttribute: peopleTypeId name: @"name"]];
[attrPos add: 1];
// AGE attribute in the fourth column
[attrs add: [graph findAttribute: peopleTypeId name: @"AGE"]];
[attrPos add: 3];
// import PEOPLE node type
STSNodeTypeLoader *ntl = [[STSNodeTypeLoader alloc] initWithRowReader: csv graph: graph type: peopleTypeId attrs: attrs attrsPos: attrPos];
[ntl setLogError: @"people.csv.log"];
[ntl run];
[csv close];
//[csv release];
//[attrs release];
//[ntl release];Specifically the EdgeTypeLoader has the following methods:
setHeadPosition and setTailPosition set which columns from the RowReader contain information about the target and source nodes respectively.
For the referenced columns, setHeadAttribute and setTailAttribute indicate the attribute identifier to be used to find the target and source node respectively. Thus, the value in that column will be used to find an object with that value for that attribute. That node will be the target or the source node, accordingly, for the new edge.
It also allows specifying the policy to follow when an edge endpoint is missing (e.g. throw an error, create the endpoint or ignore the edge) with the setTailMEP and setHeadMEP (MEP stands for MissingEndpointPolicy).
Analogously to the data import, this functionality is provided by classes in the com.sparsity.sparksee.io package for Sparkseejava, the com.sparsity.sparksee.io namespace for Sparkseenet, and in the sparksee::io namespace in Sparkseecpp.
The main classes for exporting data from Sparksee are the RowWriter class, which writes data from a row-based logical format to an external data source, and the TypeExporter class, which exports data from a Sparksee graph.
The CSVWriter class is a RowWriter implementation for writing data from a Sparksee graph into a CSV file. Alternatively, users may implement a different RowWriter to export data into other data sources.
The most important method defined by the RowWriter is the bool RowWriter#write(StringList row) method which writes data to an external storage. The RowWriter#close method must be called once the processing ends.
The CSVWriter class extends its parent class with extra functionality:
CSVWriter#open sets the path of the CSV file to be written.
The locale of the file is set by means of a case in-sensitive string argument with the following format: an optional language, a dot (‘.’) character and a coding specification.
Thus, valid locale arguments are: “en_US.UTF8”, “es_ES.ISO88591”, “.UTF8”, etc. If not specified, “en_US.iso88591” is the default locale.
A separator character is set (to limit columns) with CSVWriter#setSeparator or the quote character is set for strings with CSVWriter#setQuotes. Quoted strings can also be forced with the CSVwriter#setForcedQuotes method, or managed automatically with the CSVwriter#setAutoQuotesmethod.
The following examples show the use of the CSVWriter class, in order to add “PEOPLE” nodes with their attributes from the graph into a csv file:
CSVWriter csv = new CSVWriter();
csv.setSeparator("|");
csv.open("people.csv");
StringList row = new StringList();
// write header
row.add("ID");
row.add("NAME");
row.add("AGE");
csv.write(row);
// write rows
BooleanList quotes = new BooleanList();
quotes.add(false);
quotes.add(true); // force second column to be quoted
quotes.add(false);
csv.setForcedQuotes(quotes); // enables de quoting rules
row.clear();
row.add("1");
row.add("Woody Allen");
row.add("77");
csv.write(row);
row.clear();
row.add("2");
row.add("Scarlett Johansson");
row.add("28");
csv.write(row);
csv.close();CSVWriter csv = new CSVWriter();
csv.SetSeparator("|");
csv.Open("people.csv");
StringList row = new StringList();
// write header
row.Add("ID");
row.Add("NAME");
row.Add("AGE");
csv.Write(row);
// write rows
BooleanList quotes = new BooleanList();
quotes.Add(false);
quotes.Add(true); // force second column to be quoted
quotes.Add(false);
csv.SetForcedQuotes(quotes); // enables de quoting rules
row.Clear();
row.Add("1");
row.Add("Woody Allen");
row.Add("18");
csv.Write(row);
row.Clear();
row.Add("2");
row.Add("Scarlett Johansson");
row.Add("28");
csv.Write(row);
csv.Close();CSVWriter csv;
csv.SetSeparator(L"|");
csv.Open(L"people.csv");
StringList row;
// write header
row.Add(L"ID");
row.Add(L"NAME");
row.Add(L"AGE");
csv.Write(row);
// write rows
BooleanList quotes;
quotes.Add(false);
quotes.Add(true); // force second column to be quoted
quotes.Add(false);
csv.SetForcedQuotes(quotes); // enables de quoting rules
row.Clear();
row.Add(L"1");
row.Add(L"Woody Allen");
row.Add(L"18");
csv.Write(row);
row.Clear();
row.Add(L"2");
row.Add(L"Scarlett Johansson");
row.Add(L"28");
csv.Write(row);
csv.Close();csv = sparksee.CSVWriter()
csv.set_separator("|")
csv.open("peopleWritten.csv")
row = sparksee.StringList()
# write header
row.add("ID")
row.add("NAME")
row.add("AGE")
csv.write(row)
# write rows
quotes = sparksee.BooleanList()
quotes.add(False)
quotes.add(True) # force second column to be quoted
quotes.add(False)
csv.set_forced_quotes(quotes)
row.clear()
row.add("1")
row.add("Woody Allen")
row.add("77")
csv.write(row)
row.clear()
row.add("2")
row.add("Scarlett Johansson")
row.add("28")
csv.write(row)
csv.close()STSCSVWriter *csv = [[STSCSVWriter alloc] init];
[csv setSeparator: @"|"];
[csv open: @"people_out.csv"];
STSStringList *row = [[STSStringList alloc] init];
// write header
[row add: @"ID"];
[row add: @"NAME"];
[row add: @"AGE"];
[csv write: row];
// write rows
STSBooleanList *quotes = [[STSBooleanList alloc] init];
[quotes add: FALSE];
[quotes add: TRUE]; // force second column to be quoted
[quotes add: FALSE];
[csv setForcedQuotes: quotes]; // enables de quoting rules
[row clear];
[row add: @"1"];
[row add: @"Woody Allen"];
[row add: @"18"];
[csv write: row];
[row clear];
[row add: @"2"];
[row add: @"Scarlett Johansson"];
[row add: @"28"];
[csv write: row];
[csv close];
//[csv release];
//[row release];
//[quotes release];The output for the previous examples would be the following csv file:
The TypeExporter class exports a specific type of the graph to a external storage. There are two implementations for the TypeExporter class, regarding whether the element to be exported from the graph is a node, the NodeTypeExporter class, or an edge, the EdgeTypeExporter class. A TypeExporter retrieves all the data from the instances belonging to a node or edge type and writes it using a RowWriter.
The TypeExporter class includes the following functionalities:
TypeExporter#run executes the export process.
It is possible to register listeners to receive progress events from the TypeExporter (TypeExporter#register). This requires the user to implement the TypeExporterListener class. The frequency with which these events are generated can also be configured (TypeExporter#setFrequency).
TypeExporter#setAttributes sets the list of attributes to be exported.
The following examples export PEOPLE nodes from the graph with their attributes Name and Age, and write the information into a csv file:
Graph graph = sess.getGraph();
int peopleTypeId = graph.findType("PEOPLE");
int nameAttrId = graph.findAttribute(peopleTypeId, "Name");
int ageAttrId = graph.findAttribute(peopleTypeId, "Age");
...
// configure CSV writer
CSVWriter csv = new CSVWriter();
csv.setSeparator("|");
csv.setAutoQuotes(true);
csv.open("people.csv");
// export PEOPLE node type: Name and Age attributes
AttributeList attrs = new AttributeList();
attrs.add(nameAttrId);
attrs.add(ageAttrId);
NodeTypeExporter nte = new NodeTypeExporter(csv, graph, peopleTypeId, attrs);
nte.run();
csv.close();Graph graph = sess.GetGraph();
int peopleTypeId = graph.FindType("PEOPLE");
int nameAttrId = graph.FindAttribute(peopleTypeId, "Name");
int ageAttrId = graph.FindAttribute(peopleTypeId, "Age");
...
// configure CSV writer
CSVWriter csv = new CSVWriter();
csv.SetSeparator("|");
csv.SetAutoQuotes(true);
csv.Open("people.csv");
// export PEOPLE node type: Name and Age attributes
AttributeList attrs = new AttributeList();
attrs.Add(nameAttrId);
attrs.Add(ageAttrId);
NodeTypeExporter nte = new NodeTypeExporter(csv, graph, peopleTypeId, attrs);
nte.Run();
csv.Close();Graph * graph = sess->GetGraph();
type_t peopleTypeId = graph->FindType(L"PEOPLE");
attr_t nameAttrId = graph->FindAttribute(peopleTypeId, L"Name");
attr_t ageAttrId = graph->FindAttribute(peopleTypeId, L"Age");
...
// configure CSV writer
CSVWriter csv;
csv.SetSeparator(L"|");
csv.SetAutoQuotes(true);
csv.Open(L"people.csv");
// export PEOPLE node type: Name and Age attributes
AttributeList attrs;
attrs.Add(nameAttrId);
attrs.Add(ageAttrId);
NodeTypeExporter nte(csv, *graph, peopleTypeId, attrs);
nte.Run();
csv.Close();graph = sess.get_graph()
people_type_id = graph.new_node_type(u"PEOPLE")
name_attr_id = graph.new_attribute(people_type_id, u"Name", sparksee.DataType.STRING, sparksee.AttributeKind.INDEXED)
age_attr_id = graph.new_attribute(people_type_id, u"Age", sparksee.DataType.INTEGER, sparksee.AttributeKind.BASIC
...
# configure CSV writer
csv = sparksee.CSVWriter()
csv.set_separator(u"|")
csv.set_auto_quotes(True)
csv.open(u"people.csv")
# export PEOPLE node type: Name and Age attributes
attrs = sparksee.AttributeList()
attrs.add(name_attr_id)
attrs.add(age_attr_id)
nte = sparksee.NodeTypeExporter(csv, graph, people_type_id, attrs)
nte.run()
csv.close()STSGraph *graph = [sess getGraph];
int peopleTypeId = [graph findType: @"people"];
int nameAttrId = [graph findAttribute: peopleTypeId name: @"name"];
int ageAttrId = [graph findAttribute: peopleTypeId name: @"AGE"];
// configure CSV writer
STSCSVWriter *csv = [[STSCSVWriter alloc] init];
[csv setSeparator: @"|"];
[csv setAutoQuotes: TRUE];
[csv open: @"people_out.csv"];
// export PEOPLE node type: Name and Age attributes
STSAttributeList *attrs = [[STSAttributeList alloc] init];
[attrs add: nameAttrId];
[attrs add: ageAttrId];
STSNodeTypeExporter *nte = [[STSNodeTypeExporter alloc] initWithRowWriter: csv graph: graph type: peopleTypeId attrs: attrs];
[nte run];
[csv close];
//[csv release];
//[attrs release];
//[nte release];Specifically the EdgeTypeExporter has two set of methods to specify the source and target nodes to be exported:
setHeadPosition and setTailPosition set which columns from the RowWriter will be used to export the target and source node respectively.setHeadAttribute and setTailAttribute indicate the attribute identifier to be used to export the source and target node respectively. Thus, the value in that column of the current row will correspond to the value of that object for that attribute.This functionality is provided by classes in the com.sparsity.sparksee.script package for Sparkseejava, the com.sparsity.sparksee.script namespace for Sparkseenet, and in the sparksee::script namespace in Sparkseecpp.
Users can also interact with Sparksee through a script file, mainly to create or delete objects. Although the grammar and examples of Sparksee script language are explained in the ‘Scripting’ chapter, this section explains how to execute those scripts.
ScriptParser classThe ScriptParser class is in the com.sparsity.sparksee.script package or namespace in Sparkseejava or Sparkseenet respectively, or in the sparksee::script namespace in Sparkseecpp.
Once instantiated, this class allows the parsing and/or executing of a Sparksee script file with the method ScriptParser#parse.
The ScriptParser class sets the output and error log paths, and also sets the locale of the file to be processed. More information about the locale formats can be found in the ‘Data import’ and ‘Data export’ sections of this chapter.
Finally, the static method ScriptParser::generateSchemaScript generates and dumps the schema of a Sparksee database into an output Sparksee script file path.
The same ScriptParser class is the one that allows an interactive command-line execution:
In the case of Sparkseejava, the jar library includes a static main method together with the ScriptParser class. It just calls the ScriptParser class to provide a command-line interface to that class.
In the case of Sparkseenet and Sparkseecpp, the distribution includes a ScriptParser executable that calls the ScriptParser class to provide a command-line interface to that class.
In all cases, the application has one required argument, a Sparksee script file path, and one optional argument, a case-insensitive boolean (true or false) to force the execution of the Sparksee script file or to just parse it; true (execute) is the default.
Help is shown in case the user provides no arguments:
$ java -cp sparkseejava.jar com.sparsity.sparksee.script.ScriptParser
Wrong number of arguments.
Usage: java -cp sparkseejava.jar com.sparsity.sparksee.script.ScriptParser <script_file.des> [bool_run]
Where:
script_file.des Is the required file containing the script commands.
bool_run: True (default) = run the commands / False = just check the script.$ ScriptParser
Wrong number of arguments.
Usage: ScriptParser.exe <script_file.des> [bool_run]
Where:
script_file.des Is the required file containing the script commands.
bool_run: True (default) = run the commands / False = just check the script.$ ./ScriptParser
Wrong number of arguments.
Usage: ScriptParser <script_file.des> [bool_run]
Where:
script_file.des Is the required file containing the script commands.
bool_run: True (default) = run the commands / False = just check the script.$ python ScriptParser.py
Wrong number of arguments.
Usage: ScriptParser.py <script_file.des> [bool_run]
Where:
script_file.des Is the required file containing the script commands.
bool_run: True (default) = run the commands / False = just check the script.This functionality is provided by classes in the com.sparsity.sparksee.algorithms package for Sparkseejava, the com.sparsity.sparksee.algorithms namespace for Sparkseenet, and in the sparksee::algorithms namespace in Sparkseecpp.
Sparksee API includes a set of generalist graph algorithms which can be categorized as follows:
To traverse a graph is to visit its nodes starting from one of them. Several filters and restrictions can be specified for the traversal:
There are two implementations available for this algorithm:
TraversalBFS class implements the traversal using a breadth-first search strategy.TraversalDFS class implements the traversal using a depth-first search strategy.All previous traversal classes have an iterator pattern. Once instantiated and configured, the user must call Traversal#hasNext and Traversal#next in order to visit the next node. Take into account that is strongly recommended to close (delete for Sparkseecpp) the traversal instance as soon as it is no longer needed.
The following examples navigate three hops through outgoing edges visiting only PEOPLE nodes:
Graph graph = sess.getGraph();
long src = ... // source node identifier
...
TraversalDFS dfs = new TraversalDFS(sess, src);
dfs.addAllEdgeTypes(EdgesDirection.Outgoing);
dfs.addNodeType(graph.findType("PEOPLE"));
dfs.setMaximumHops(3);
while (dfs.hasNext())
{
System.out.println("Current node " + dfs.next()
+ " at depth " + dfs.getCurrentDepth());
}
dfs.close();Graph graph = sess.GetGraph();
long src = ... // source node identifier
...
TraversalDFS dfs = new TraversalDFS(sess, src);
dfs.AddAllEdgeTypes(EdgesDirection.Outgoing);
dfs.AddNodeType(graph.FindType("PEOPLE"));
dfs.SetMaximumHops(3);
while (dfs.HasNext())
{
System.Console.WriteLine("Current node " + dfs.Next()
+ " at depth " + dfs.GetCurrentDepth());
}
dfs.Close();Graph * graph = sess->GetGraph();
oid_t src = ... // source node identifier
...
TraversalDFS dfs(*sess, src);
dfs.AddAllEdgeTypes(Outgoing);
dfs.AddNodeType(graph->FindType(L"PEOPLE"));
dfs.SetMaximumHops(3);
while (dfs.HasNext())
{
std::cout << "Current node " << dfs.Next()
<< " at depth " << dfs.GetCurrentDepth() << std::endl;
}graph = sess.get_graph()
src = ... # source node identifier
...
dfs = sparksee.TraversalDFS(sess, src)
dfs.add_all_edge_types(sparksee.EdgesDirection.OUTGOING)
dfs.add_node_type(graph.find_type(u"PEOPLE"))
dfs.set_maximum_hops(3)
while dfs.has_next():
print "Current node ", dfs.next(), " at depth ", dfs.get_current_depth()
dfs.close()STSGraph *graph = [sess getGraph];
long long src = ... // source node identifier
...
STSTraversalDFS *dfs = [[STSTraversalDFS alloc] initWithSession: sess node: src];
[dfs addAllEdgeTypes: STSOutgoing];
[dfs addNodeType: [graph findType: @"PEOPLE"]];
[dfs setMaximumHops: 3];
while ([dfs hasNext])
{
NSLog(@"Current node %lld at depth %d\n", [dfs next], [dfs getCurrentDepth]);
}
[dfs close];
//[dfs release];The Context is a complementary class that has a very similar interface and provides the same functionality as the Traversal class. Instead of visiting each node using an iterator pattern, Context class returns an Objects instance which contains all the “visited” nodes. Similarly to what happens with the Traversal instances, all Context instances must be closed (or deleted in the case of Sparkseecpp) when they are no longer in use.
The following examples repeat the three-hop navigation but this time using the Context class:
Graph graph = sess.getGraph();
long src = ... // source node identifier
...
Context ctx = new Context(sess, src);
ctx.addAllEdgeTypes(EdgesDirection.Outgoing);
ctx.addNodeType(graph.findType("PEOPLE"));
ctx.setMaximumHops(3, true);
Objects objs = ctx.compute();
...
objs.close();
ctx.close();Graph graph = sess.GetGraph();
long src = ... // source node identifier
...
Context ctx = new Context(sess, src);
ctx.AddAllEdgeTypes(EdgesDirection.Outgoing);
ctx.AddNodeType(graph.FindType("PEOPLE"));
ctx.SetMaximumHops(3, true);
Objects objs = ctx.Compute();
...
objs.Close();
ctx.Close();Graph * graph = sess->GetGraph();
oid_t src = ... // source node identifier
...
Context ctx(*sess, src);
ctx.AddAllEdgeTypes(Outgoing);
ctx.AddNodeType(graph->FindType(L"PEOPLE"));
ctx.SetMaximumHops(3, true);
Objects * objs = ctx.Compute();
...
delete objs;graph = sess.get_graph()
src = ... # source node identifier
...
ctx = sparksee.Context(sess, src)
ctx.add_all_edge_types(sparksee.EdgesDirection.OUTGOING)
ctx.add_node_type(graph.find_type(u"PEOPLE"))
ctx.set_maximum_hops(3, True)
objs = sparksee.Context.compute(ctx)
...
objs.close();STSGraph *graph = [sess getGraph];
long long src = ... // source node identifier
...
STSContext *ctx = [[STSContext alloc] initWithSession: sess node: src];
[ctx addAllEdgeTypes: STSOutgoing];
[ctx addNodeType: [graph findType: @"people"]];
[ctx setMaximumHops: 3 include: TRUE];
STSObjects * objs = [ctx compute];
...
[objs close];
[ctx close];
//[ctx release];To find a shortest path in a graph is to discover which edges and nodes should be visited in order to go from one node to another in the fastest way. Several filters and restrictions can be specified in order to find the most appropriate path:
All Sparksee shortest path implementations inherit from a specific ShortestPath subclass called SinglePairShortestPath. Additionally, this class defines the following methods to retrieve the results:
SinglePairShortestPath#getPathAsEdges: returns the computed shortest path as an edge identifier sequence.SinglePairShortestPath#getPathAsNodes: returns the computed shortest path as a node identifier sequence.In fact, there are two specific implementations of SinglePairShortestPath:
SinglePairShortestPathBFS class which solves the problem using a breadth-first search strategy. This implementation solves the problem of unweighted graphs, as it assumes all edges have the same cost.SinglePairShortestPathDijkstra class which solves the problem based on the well-known Dijkstra’s algorithm. This algorithm solves the shortest path problem for a graph with positive edge path costs, producing a shortest path tree.
With the same class the user may add weights to the edges of the graph using the addWeightedEdgeType method. That attribute will be used during the computation of the algorithm to retrieve the cost of that edge. The class also includes the getCost method to retrieve the cost of the computed shortest path.
The ShortestPath class and all its subclasses have a close method which must be called once the instances are no longer in use in order to free internal resources (or delete them in the case of Sparkseecpp).
The following examples show the use of the Dijkstra shortest path:
Graph graph = sess.getGraph();
long src = ... // source node identifier
long dst = ... // destination node identifier
...
SinglePairShortestPathDijkstra spspd = new SinglePairShortestPathDijkstra(sess, src, dst);
spspd.addAllNodeTypes();
int roadTypeId = graph.findType("ROAD");
int distanceAttrId = graph.findAttribute(roadTypeId, "DISTANCE");
spspd.addWeightedEdgeType(roadTypeId, EdgesDirection.Outgoing, distanceAttrId);
spspd.setMaximumHops(4);
spspd.run();
if (spspd.exists())
{
double cost = spspd.getCost();
OIDList nodes = spspd.getPathAsNodes();
OIDList edges = spspd.getPathAsEdges();
}
spspd.close();Graph graph = sess.GetGraph();
long src = ... // source node identifier
long dst = ... // destination node identifier
...
SinglePairShortestPathDijkstra spspd = new SinglePairShortestPathDijkstra(sess, src, dst);
spspd.AddAllNodeTypes();
int roadTypeId = graph.FindType("ROAD");
int distanceAttrId = graph.FindAttribute(roadTypeId, "DISTANCE");
spspd.AddWeightedEdgeType(roadTypeId, EdgesDirection.Outgoing, distanceAttrId);
spspd.SetMaximumHops(4);
spspd.Run();
if (spspd.Exists())
{
double cost = spspd.GetCost();
OIDList nodes = spspd.GetPathAsNodes();
OIDList edges = spspd.GetPathAsEdges();
}
spspd.Close();Graph * graph = sess->GetGraph();
oid_t src = ... // source node identifier
oid_t dst = ... // destination node identifier
...
SinglePairShortestPathDijkstra spspd(*sess, src, dst);
spspd.AddAllNodeTypes();
type_t roadTypeId = graph->FindType(L"ROAD");
attr_t distanceAttrId = graph->FindAttribute(roadTypeId, L"DISTANCE");
spspd.AddWeightedEdgeType(roadTypeId, Outgoing, distanceAttrId);
spspd.SetMaximumHops(4);
spspd.Run();
if (spspd.Exists())
{
double cost = spspd.GetCost();
OIDList * nodes = spspd.GetPathAsNodes();
OIDList * edges = spspd.GetPathAsEdges();
...
delete nodes;
delete edges;
}graph = sess.get_graph()
src = ... # source node identifier
dst = ... # destination node identifier
...
spspd = sparksee.SinglePairShortestPathDijkstra(sess, src, dst)
spspd.add_all_node_types()
road_type_id = graph.find_type("ROAD")
distance_attr_id = graph.find_attribute(road_type_id, "DISTANCE")
spspd.add_weighted_edge_type(road_type_id, sparksee.EdgesDirection.OUTGOING, distance_attr_id)
spspd.set_maximum_hops(4)
spspd.run()
if spspd.exists():
cost = spspd.get_cost()
nodes = spspd.get_path_as_nodes()
edges = spspd.get_path_as_edges()
...
nodes.close()
edges.close()
spspd.close()STSGraph *graph = [sess getGraph];
long long src = ... // source node identifier
long long dst = ... // destination node identifier
...
STSSinglePairShortestPathDijkstra *spspd = [[STSSinglePairShortestPathDijkstra alloc] initWithSession: sess src: src dst: dst];
[spspd addAllNodeTypes];
int roadTypeId = [graph findType: @"ROAD"];
int distanceAttrId = [graph findAttribute: roadTypeId name: @"DISTANCE"];
[spspd addWeightedEdgeType: roadTypeId dir: STSOutgoing attr: distanceAttrId];
[spspd setMaximumHops: 4];
[spspd run];
if ([spspd exists])
{
double cost = [spspd getCost];
STSOidList * nodes = [spspd getPathAsNodes];
STSOidList * edges = [spspd getPathAsEdges];
...
}
[spspd close];
[spspd release];
}Discovering the connected components is a common problem in graph theory. A connected component is a subgraph where any two nodes are connected to each other by paths, whilst at the same time it is not connected to any additional node in the supergraph.
Connectivity is the basic class for all the different implementations. Several filters and restrictions can be specified in order to find the connected components:
[0..C-1] where C is the number of different connected components. Note that the results are not automatically updated in the case that the graph topology is updated (node or edge object added or removed).Depending on whether the graph is managed as a directed or undirected graph, there are two types of Connectivity subclasses:
StrongConnectivity class solves the connected components problem for directed graphs. This class provides methods for restricting which edge types can be traversed during the computation as well as the direction of those edges. The implementation for this class is the StrongConnectivityGabow class that uses the Gabow’s algorithm strategy.
WeakConnectivity class solves the connected components problem for undirected graphs, where all edges are considered as undirected. Note that if the graph contains directed edge types, these edges will be managed as if they were simply undirected edge types. The implementation for this class is the WeakConnectivityDFS class that use the DFS strategy.
Additionally the ConnectedComponents class helps the user manage the result of a connectivity computation. It retrieves the number of connected components, the connected component identifier for each node, and the size of a certain connected component or all the elements in a connected component.
All the connectivity classes and subclasses have a close method in order to free resources as soon as the instances are no longer in use (deleted in the case of Sparkseecpp).
StrongConnectivityGabow scg = new StrongConnectivityGabow(sess);
scg.addAllNodeTypes();
scg.addAllEdgeTypes(EdgesDirection.Outgoing);
scg.run();
ConnectedComponents cc = scg.getConnectedComponents();
for (int i = 0; i < cc.getCount(); i++)
{
System.out.println("# component: " + i + " size: " + cc.getSize(i));
Objects objs = cc.getNodes(i);
...
objs.close();
}
cc.close();
scg.close();StrongConnectivityGabow scg = new StrongConnectivityGabow(sess);
scg.AddAllNodeTypes();
scg.AddAllEdgeTypes(EdgesDirection.Outgoing);
scg.Run();
ConnectedComponents cc = scg.GetConnectedComponents();
for (int i = 0; i < cc.GetCount(); i++)
{
System.Console.WriteLine("# component: " + i + " size: " + cc.GetSize(i));
Objects objs = cc.GetNodes(i);
...
objs.Close();
}
cc.Close();
scg.Close();StrongConnectivityGabow scg(*sess);
scg.AddAllNodeTypes();
scg.AddAllEdgeTypes(Outgoing);
scg.Run();
ConnectedComponents * cc = scg.GetConnectedComponents();
for (int i = 0; i < cc->GetCount(); i++)
{
std::cout << "# component: " << i << " size: " << cc->GetSize(i) << std::endl;
Objects * objs = cc->GetNodes(i);
...
delete objs;
}
delete cc;scg = sparksee.StrongConnectivityGabow(sess)
scg.add_all_node_types()
scg.add_all_edge_types(sparksee.EdgesDirection.OUTGOING)
scg.run()
cc = scg.get_connected_components()
for i in range(0, cc.get_count()):
print "# component: ", i, " size: ", cc.get_size(i)
objs = cc.get_nodes(i)
...
objs.close()
cc.close()
scg.close()STSStrongConnectivityGabow *scg = [[STSStrongConnectivityGabow alloc] initWithSession: sess];
[scg addAllNodeTypes];
[scg addAllEdgeTypes: STSOutgoing];
[scg run];
STSConnectedComponents * cc = [scg getConnectedComponents];
for (int ii = 0; ii < [cc getCount]; ii++)
{
NSLog(@"# component: %d size: %lld\n", ii, [cc getSize: ii]);
STSObjects * objs = [cc getNodes: ii];
...
[objs close];
}
[cc close];
[scg close];
//[scg release];Detecting communities is a common problem in graph theory. A community is a subgraph where the set of nodes are densely connected.
CommunityDetection is the basic class for all the different implementations. Several filters and restrictions can be specified in order to find the communities:
In addition the abstract class, DisjointCommunityDetection inherits from ‘CommunityDetection’ and also adds the specific operations for not overlapping community detection:
[0..C-1] where C is the number of different communities. Note that the results are not automatically updated in the case that the graph topology is updated (node or edge objects added or removed).The only community detection algorithm currently implemented is an algorithm for undirected graphs. As a result, the operations to set the valid EdgeTypes does not have a direction argument. All the added types will be used in both directions even when the edge type is directed.
CommunitiesSCD class solves the not overlapping community detection problem for undirected graphs. This class provides methods for restricting which edge types can be traversed during the computation. The implementation for this class uses the Scalable Community Detection algorithm based on the paper High quality, scalable and parallel community detection for large real graphs by Arnau Prat-Perez, David Dominguez-Sal, Josep-Lluis Larriba-Pey - WWW 2014.Additionally the DisjointCommunities class helps the user manage the result of a disjoint community detection algorithm. It retrieves the number of communities, the community identifier for each node, and the size of a certain community or all the elements in a community.
All the community classes and subclasses have a close method in order to free resources as soon as the instances are no longer in use (deleted in the case of Sparkseecpp).
CommunitiesSCD commSCD = new CommunitiesSCD(sess);
commSCD.addAllEdgeTypes();
commSCD.addAllNodeTypes();
commSCD.run();
DisjointCommunities dcs = commSCD.getCommunities();
for (long ii = 0; ii < dcs.getCount(); ii++)
{
System.out.println("Community "+ii+" has "+dcs.getSize(ii)+" nodes.");
Objects dcsNodes = dcs.getNodes(ii);
...
dcsNodes.close();
}
dcs.close();
commSCD.close();CommunitiesSCD commSCD = new CommunitiesSCD(sess);
commSCD.AddAllEdgeTypes();
commSCD.AddAllNodeTypes();
commSCD.Run();
DisjointCommunities dcs = commSCD.GetCommunities();
for (long ii = 0; ii < dcs.GetCount(); ii++)
{
System.Console.WriteLine("Community "+ii+" has "+dcs.GetSize(ii)+" nodes.");
Objects dcsNodes = dcs.GetNodes(ii);
...
dcsNodes.Close();
}
dcs.Close();
commSCD.Close();CommunitiesSCD commSCD(*sess);
commSCD.AddAllEdgeTypes();
commSCD.AddAllNodeTypes();
commSCD.Run();
DisjointCommunities *dcs = commSCD.GetCommunities();
for (sparksee::gdb::int64_t ii = 0; ii < dcs->GetCount(); ii++)
{
std::cout << "# community: " << ii << " size: " << cc->GetSize(ii) << std::endl;
Objects *dcsNodes = dcs->GetNodes(ii);
...
delete dcsNodes;
}
delete dcs;commmSCD = sparksee.CommunitiesSCD(sess)
commmSCD.add_all_edge_types()
commmSCD.add_all_node_types()
commmSCD.run()
dcs = commmSCD.get_communities()
for ii in range(0, dcs.get_count()):
print "Community ", ii, " has ", dcs.get_size(ii), " nodes."
dcsNodes = dcs.get_nodes(ii)
...
dcsNodes.close()
dcs.close()
commmSCD.close()STSCommunitiesSCD *commSCD = [[STSCommunitiesSCD alloc] initWithSession: sess];
[commSCD addAllEdgeTypes];
[commSCD addAllNodeTypes];
[commSCD run];
STSDisjointCommunities *dcs = [commSCD getCommunities];
for (long long ii = 0; ii < [dcs getCount]; ii++)
{
NSLog(@"# Community: %d size: %lld\n", ii, [dcs getSize: ii]);
STSObjects *dcsNodes = [dcs getNodes: ii];
...
[dcsNodes close];
}
[dcs close];
[commSCD close];
//[commSCD release];The PageRank is the algorithm behind the original Google Search Engine and is used to rank the relevance of nodes in a graph. The PageRank of a node can be seen as the probability of finishing a Random Walk at a the given node in the graph. PageRank is an iterative algorithm where the rank of a node is computed based on the ranks incident neighbors from the previous iteration. Then, nodes with more incident connections (specially connections from nodes with a large Page Rank) will have a larger rank and thus a larger probability to be the final node in the Random Walk. The PageRank is widely used in recommender systems. The algorithm can be configured with the following parameters:
Once the PageRank algorithm is been run, a typical pattern is to run a TopK over the PageRank attribute to find the most relevant nodes.
PageRank pr = new PageRank(sess);
pr.addAllEdgeTypes(EdgesDirection.Outgoing);
pr.addAllNodeTypes();
pr.setOutputAttributeType(prAttr);
pr.setNumIterations(50);
pr.run();
KeyValues kv = graph.topK(prAttr, Order.Descendent, 100);
while(kv.hasNext())
{
KeyValue kvp = kv.next();
long oidAux = kvp.getKey();
Value v = kvp.getValue();
...
}
kv.close();
pr.close();PageRank pr = new PageRank(sess);
pr.AddAllEdgeTypes(EdgesDirection.Outgoing);
pr.AddAllNodeTypes();
pr.SetOutputAttributeType(prAttr);
pr.SetNumIterations(50);
pr.Run();
KeyValues kv = graph.TopK(prAttr, Order.Descendent, 100);
while(kv.HasNext())
{
KeyValue kvp = kv.Next();
long oidAux = kvp.GetKey();
Value v = kvp.GetValue();
...
}
kv.Close();
pr.Close();sparksee::PageRank pr(*sess);
pr.AddAllEdgeTypes(Outgoing);
pr.AddAllNodeTypes();
pr.SetOutputAttributeType(prAttr);
pr.SetNumIterations(50);
pr.Run();
KeyValues* kv = graph.TopK(prAttr, Descendent, 100);
while(kv.HasNext())
{
KeyValue kvp;
kv.Next(kvp);
oid_t oidAux = kvp.GetKey();
Value v = kvp.GetValue();
...
}
delete kv;pr = sparksee.PageRank(sess)
pr.add_all_edge_types(sparksee.Direction.OUTGOING)
pr.add_all_node_types()
pr.set_output_attribute(prAttr)
pr.set_num_iterations(50)
pr.run()
kv = g.top_k(prAttr, sparksee.Order.DESCENDENT, 100)
for kvp in kv:
oid = kvp.get_key()
v = kvp.get_value()
...
kv.close()
pr.close()STSPageRank *pr = [[STSPageRank alloc] initWithSession: sess];
[pr addAllEdgeTypes: STSOutgoing];
[pr addAllNodeTypes];
[pr setOutputAttributeType: prAttr]
[pr setNumIterations: 50]
[pr run];
STSKeyValues* kv = [g topkWithAttr: prAttr order: STSDescendent k: 100];
STSKeyValue* kvp = [[STSKeyValue alloc] init];
while ([kv hasNext]) {
[kv nextKeyValue: kvp];
long long oid = [kvp getKey];
STSValue* value = [kvp getValue];
...
}
[kv close];
[pr close];2-opt and 3-opt are simple local search algorithms for solving the travelling salesman problem (TSP) and related network optimization problems. The main idea behind 2-opt is to take a tour that crosses over itself and reorder it so that it does not. In other words, in each step, 2-opt removes two edges (connections) and tries to reconnect the tour by reducing the total cost. On the other hand, 3-opt removes three connections and then examines 7 different ways of reconnecting the tour in order to find the optimal one.
Both 2-opt and 3-opt algorithms are implemented in KOpt class. Similar to some other algorithms in the library, they are executed on a subgraph constructed of nodes and edges of given types. In addition, the edge weight attribute representing the travel cost needs to be explicitly defined:
KOpt kOpt = new KOpt(sess);
kOpt.addNodeType(nodeType);
kOpt.addEdgeType(edgeType, EdgesDirection.Outgoing);
kOpt.setEdgeWeightAttributeType(weightType);KOpt kOpt = new KOpt(sess);
kOpt.AddNodeType(nodeType);
kOpt.AddEdgeType(edgeType, EdgesDirection.Outgoing);
kOpt.SetEdgeWeightAttributeType(weightType);KOpt kOpt(*session);
kOpt.AddNodeType(nodeType);
kOpt.AddEdgeType(edgeType, Outgoing);
kOpt.SetEdgeWeightAttributeType(weightType);k_opt = sparksee.KOpt(sess)
k_opt.add_node_type(node_type)
k_opt.add_edge_type(edge_type, sparksee.EdgesDirection.OUTGOING)
k_opt.set_edge_weight_attribute_type(weight_type)STSKOpt *kOpt = [[STSKOpt alloc] initWithSession: sess];
[kOpt addNodeType: nodeType];
[kOpt addEdgeType: edgeType dir: STSOutgoing];
[kOpt setEdgeWeightAttributeType: weightType];Optionally, the algorithms can be given an initial tour to be used as a starting point of the optimization process. However, if the initial tour is not given, the algorithms will seamlessly create one using greedy nearest neighbour approach. In addition, the algorithms can be also configured to run only for limited number of iterations, where iteration is defined as a single step in which tour was improved:
Finally, the algoritms are executed by calling TwoOptRun() or ThreeOptRun(). The result tour can be obtain using getter method GetCurrentTour():
k_opt.run_two_opt()
k_opt.get_current_tour()
k_opt.run_three_opt()
k_opt.get_current_tour()
k_opt.close()Sparksee provides two mechanisms to capture and react to errors, depending on their nature: exceptions and callbacks.
This is the main error handling mechanism used by Sparksee, and is used to report errors that are produced by a wrong usage of the database (e.g. adding a node of an unexisting type, creating an edge between unexisting nodes, etc.). Such errors, leave the database in a valid and defined state from Sparksee’s perspective, so these can be safely reported and the control flow to be tansfered to the application, where the user must handle them accordingly. The following are the different types of reported exceptions.
Objects#Any() operation.There are errors from which Sparksee cannot be recovered. On such errors, which are referred as Unrecoverable Errors, the execution control cannot be transfered to the user using an exception, since one has no guarantees that Sparksee ends up in a defined state that allows the user to continue operating with the database. The only action Sparksee can do is to signal a SIGABRT to abort the application.
Even though, in such a situation, Sparksee is forced to abort the application, it offers a mechanism to capture such errors as soon as they are detected, and to let the user to take some last stand actions before Sparksee crashed the application by sending the SIGABRT signal.
Such mechanism takes the form of a callback function that is set using the Sparksee object just right after it is created, and before a database is opened or created. That is, an Unrecoverable Error can never occur during creating a Sparksee object and the first time it can happen is during creating or openning an existing database.
The callback is a function that takes as an argument the code of the type of triggered error. Currently, two types of Unrecoverable Errors exist:
SystemCallError: This error is triggered when a system call, deep in the call stack throws an error out of which Sparksee cannot be recovered from.
InvalidChecksum: This error is triggered when an invalid checksum is detected when reading data from disk.
After returning from the callback, Sparksee immediately sends the signal. This feature is currently available only through the C++ and Python apis.
#include "gdb/Sparksee.h"
#include "gdb/Database.h"
#include "gdb/Session.h"
#include "gdb/Graph.h"
#include "gdb/Objects.h"
#include "gdb/ObjectsIterator.h"
using namespace sparksee::gdb;
void Callback(UnrecoverableError err)
{
switch(err)
{
case SystemCallError:
...
break;
case InvalidChecksum:
...
break;
};
}
int main(int argc, char *argv[])
{
SparkseeConfig cfg(L"sparksee.cfg");
cfg.SetClientId(L"Your client identifier");
cfg.SetLicenseId(L"Your license identifier");
Sparksee *sparksee = new Sparksee(cfg);
sparksee->SetUnrecoverableErrorCallback(Callback);
Database * db = sparksee->Create(L"HelloSparksee.gdb", L"HelloSparksee");
Session * sess = db->NewSession();
Graph * graph = sess->GetGraph();
// Use 'graph' to perform operations on the graph database
delete sess;
delete db;
delete sparksee;
return EXIT_SUCCESS;
}import sparksee
def callback(err):
if err == sparksee.UnrecoverableError.SYSTEM_CALL_ERROR:
...
if err == sparksee.UnrecoverableError.INVALID_CHECKSUM:
...
def main():
cfg = sparksee.SparkseeConfig("sparksee.cfg")
cfg.set_client_id("Your client identifier")
cfg.set_license_id("Your license identifier")
sparks = sparksee.Sparksee(cfg)
sparks.set_unrecoverable_error_callback(callback)
db = sparks.create(u"Hellosparks.gdb", u"HelloSparksee")
sess = db.new_session()
graph = sess.get_graph()
# Use 'graph' to perform operations on the graph database
sess.close()
db.close()
sparks.close()
if __name__ == '__main__':
main()One can express and execute declarative queries using the Sparksee Cypher query language, which is an implementation of the Open Cypher query language (with some particularities). For details about the language, please refer to the SparkseeCypherReference manual.
To create a Query, the method Session#newQuery recieves an enum specifying the language to use. Only two possible values are currently supported: SparkseeCypher, to execute queries in Sparksee Cypher query language, and SparkseeAlgebra, which is the internal query representation which is not publicly documented and meant to be used only by Sparksee developers.
Once the query is created, the query can be executed through the Query#execute method, which takes the query to execute as a string, plus a parameter indicating if we want the returned ResultSet to be reiterable (making a result reiterable imples increasing the memory consumption). The ResultSet is an iterator with the following main methods:
ResultSet#next: advances to the next row. Initially, the iterator is set to before the first row.ResultSet#getNumColumns: gets the number of columns in the ResultSetResultSet#getColumnName: gets the name of the column by its index (from 0 to n-1)ResultSet#getColumnDatatype: gets the datatype of the column by its index (from 0 to n-1)ResultSet#getColumnIndex: gets the index of a column by its nameResultSet#getColumn: gets a column by its indexThe method ResultSet#getColumn returns column Value for the current row of the iterator, which is a regular Sparksee Value containing the value, which must be queried with the proper datatype.
Finally, methods Query#setDynamic (to set dynamic parameters) and Query#setStream (to set streams) are not yet supported for Sparksee Cypher queries and will be supported in future releases.
Query query = sess.newQuery(SparkseeCypher);
ResultSet rs = query.execute("MATCH (n:actor) RETURN n, n.name, n.age, n.weight", false)
while(rs.next())
{
System.out.print(rs.getColumn(0).GetLong());
System.out.print(" "+rs.getColumn(1).getString());
System.out.print(" "+rs.getColumn(2).getInteger());
System.out.println(" "+rs.getColumn(3).getDouble());
}
rs.close();
query.close()Query query = sess.NewQuery(SparkseeCypher);
ResultSet rs = query.Execute("MATCH (n:actor) RETURN n, n.name, n.age, n.weight", false)
while(rs.Next())
{
System.Console.Write(rs.getColumn(0).GetLong());
System.Console.Write(" "+rs.getColumn(1).getString());
System.Console.Write(" "+rs.getColumn(2).getInteger());
System.Console.WriteLine(" "+rs.getColumn(3).getDouble());
}
rs.Close();
query.Close()Query* query = sess->NewQuery(SparkseeCypher);
ResultSet* rs = query->Execute("MATCH (n:actor) RETURN n, n.name, n.age, n.weight", false)
while(rs->Next())
{
std::cout << rs.getColumn(0).GetLong();
std::cout << " " << rs.getColumn(1).getString();
std::cout << " " << rs.getColumn(2).getInteger();
std::cout << " " << rs.getColumn(3).getDouble() << std::endl;
}
delete rs;
delete query;Query* query = sess->NewQuery(SparkseeCypher);
ResultSet* rs = query->Execute("MATCH (n:actor) RETURN n, n.name, n.age, n.weight", False)
while rs.next():
print rs.get_column(0).get_long()
print " "+str(rs.get_column(1).get_string())
print " "+str(rs.get_column(2).get_integer())
print " "+str(rs.get_column(3).get_double())+"\n"STSQuery* query = [sess createQuery: SparkseeCypher]
STSResultSet* rs = [query execute: @"MATCH (n:actor) RETURN n, n.name, n.age, n.weight" reiterable: false]
while ([rs next])
{
NSLog(@"%ld", [[rs getColumn: 0] getLong]);
NSLog(@"%S", [[rs getColumn: 1] getString]);
NSLog(@"%d", [[rs getColumn: 2] getInteger]);
NSLog(@"%lf", [[rs getColumn: 3] getDouble]);
}
[rs close]
[query close]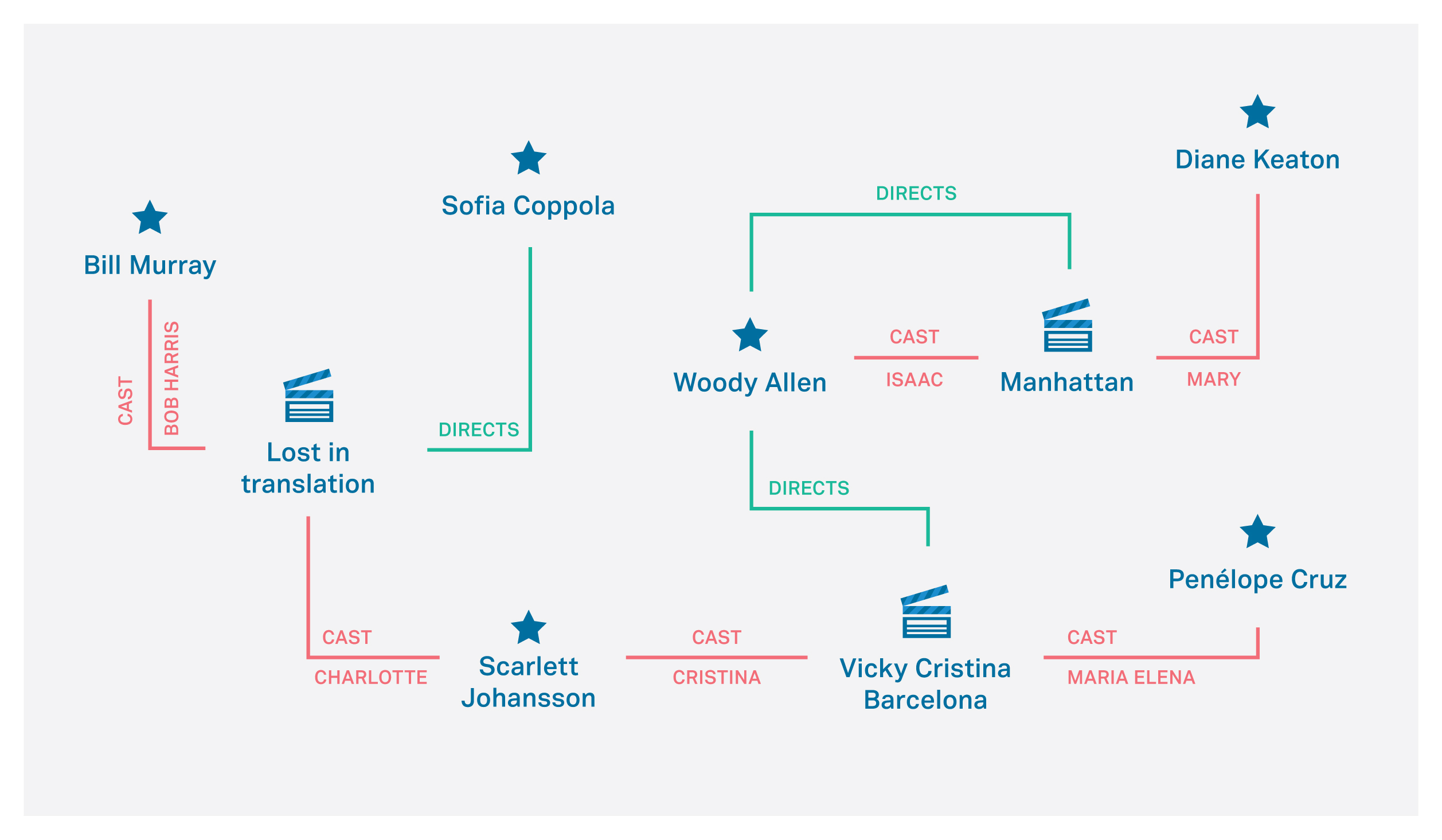{kind=link}